关于
-
任务
-
单词
- 高级语言中有实在意义的最小语法单位,字符组成(关键字?)
- 包括:
- 基本字:
void int float等 - 标识符:变量名,函数名等
- 整常数:例如 a*50 中的50
- 运算符:
+ - * / =等 - 界限符:
{} '' ; ()等
- 基本字:
-
转换
- 对基本字、运算符、界限符的转换
- 标识符的转换
- 常数的转换
- 转换完成后的格式:(类号,内码)
描述词法规则的有效工具是正规式和有限自动机
词法分析
编译的第一阶段,在单词的级别上分析和翻译源程序。
理论基础
有限自动机理论
- 有限自动机理论与正规文法、正规式之间在描述语言方面有一一对应的关系。
正规集
由正规文法产生的语言
正规集是集合,可有穷也可无穷。可通过正规式来形式化表示。
正规式

诶,蛙趣,笔者被做掉了,正规文法,正规式,正规集傻傻分不清楚。–TODO–
有限自动机
有限自动机是一种识别装置,它能准确地识别正规集。它为词法分析程序的构造提供了方法和工具。
有限自动机是具有离散输入输出系统的数学模型,它具有有限数目的内部状态,系统可以根据当前所处的状态和面临的输入字符决定系统的后继行为。其当前状态概括了过去输入处理的信息。
基本模型

包含确定的有限状态自动机 DFA 和 不确定的有限状态自动机 NFA
考试考点如下,笔者用不着,不学
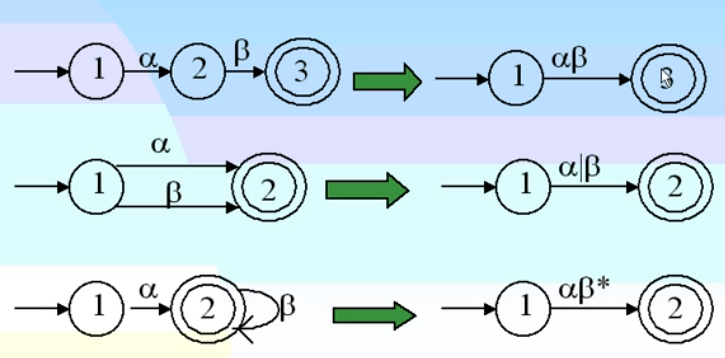
NFA确定化 有限状态自动机的简化
有限状态自动机可以和正规式互相转化,正向是简化,反向是分裂
词法分析程序
扫描源程序字符串,按照词法规则识别出一个个正确的单词,并转换为相应的二元式形式(类号,内码),交给语法分析使用。
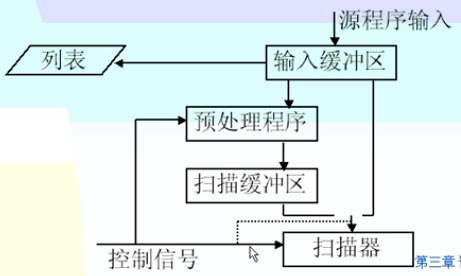
- 预处理
- 源程序中包含注解部分,还有无用的空格、跳格、回车换行等编辑字符,它们与词法分析无关。
- 一行语句结束应配上一个特殊字符说明。
- 有些语言要识别标号区,区分标号语句,找出续行符连接成完整语句等。
- 输出源程序清单以便复核。
- 预处理程序任务:
- 从输入缓冲区中读取源程序,预处理后送入扫描缓冲区。此时,扫描缓冲区中的字符都是有效字符。
- 词法分析程序这时可以再对扫描缓冲区进行扫描
- 超前搜索
一般高级语言不必超前搜索
但有些对关键字不加保护的语言,单词间没有明确界符,要在上下文环境中识别单词,这时需要超前搜索。
词法分析程序输出格式
二元式(类号,内码):每个单词对应一个二元式。其中类号用整数表示,类号既可区分单词种类,又可便于程序处理。
类号用于区分单词的种类,考虑的原则是:
- 每个基本字占有一个类号,内码缺省;
- 各种标识符统一为一类,由内码来区分不同的标识符名。通常将各标识符的符号表入口地址作为其内码。
- 对于常量,以常量的数据类型区分不同类号,对每类设置相应常量表。各常量在其常量表中的入口地址作为其内码。
- 对于界符,通常一个符号一个类号,内码缺省,
单词分类
以C语言为例
基本字(关键字、保留字)
标识符:变量名、数组名、函数名、过程名
常量
运算符
边界符(界符):
. , ; ( ) : {}等,有时把运算符当做边界符
词法分析程序设计方法
- 写出该语言的词法规则。
- 把词法规则转换为相应的状态转换图,
- 把各转换图的初态连在一起,构成识别该语言的自动机
- 设计扫描器
- 把扫描器作为语法分析的一个过程,当语法分析需要一个单词时,就调用扫描器。
- 扫描器从初态出发,当识别一个单词便进入终态,送出二元式。
可以用状态矩阵代替状态图,以便于计算机处理。
词法分析程序=状态转换图+控制程序
控制程序简单,关键是构造状态转换矩阵及其相应的语义动作。可根据单词的正规式及其相应的语义动作自动产生词法分析程序