语法规则如何表示
- BNF(巴科斯范式):
A::=B|C-> 表示A定义为B或C
语法分析的方法
-
推导(Derive)和归约(Reduce)
-
推导
- 最左推导、最右推导
- 最右推导:每次推导都把最右方的字母按照规则转化为标识符或者常量
- 最左推导、最右推导
-
归约(推导的逆过程)
- 最右归约、最左归约
- 最左归约:每次归约都把最左方的标识符或者常量按照规则转化为字母
- 最右归约、最左归约
两个栗子
语法规则
|
|
例子一
- 下图中,箭头方向是最右推导,箭头反方向最左归约
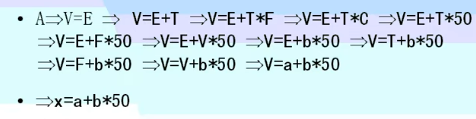
例子二
- 下图中,箭头方向是最左推导,箭头反方向最右归约
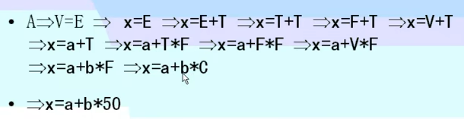
语法分析过程
语法分析过程也可以用一颗倒着的树来表示,这棵树叫语法树,如下
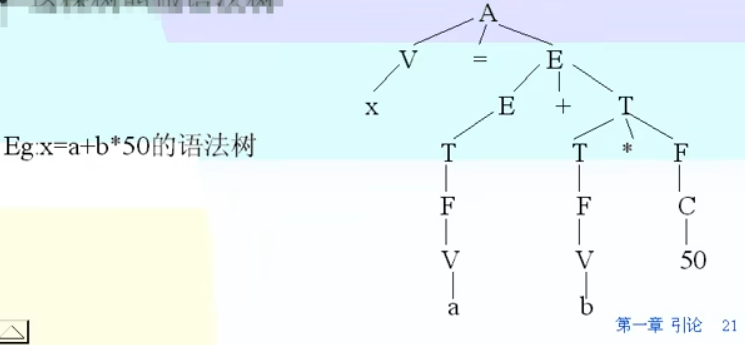
解析过程思维导图
仅做理解使用
语法规则
|
|
赋值语句
例如var a=b*10,可以按照语法规则解析时,思维流程图为:
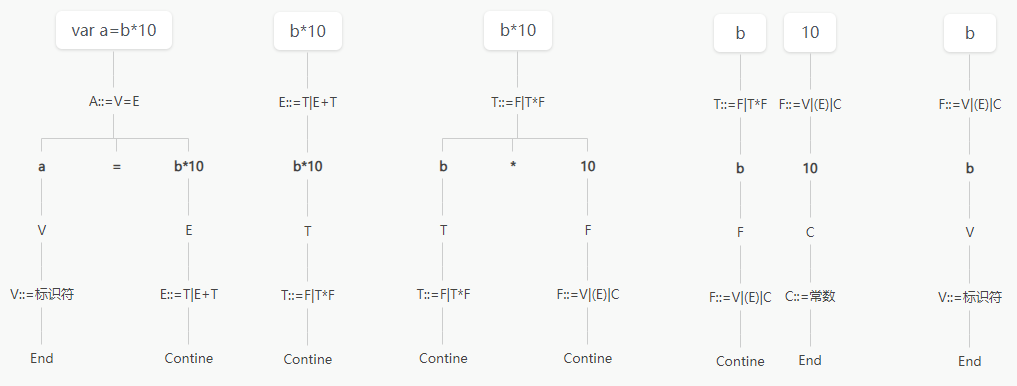
语法规则会递归解析,直到变成最开始的定义
步骤为:
- 原式子
- 处理原式子的规则
- 处理后的子式子
- 按照刚才处理的规则,子式子对应的所属
- 查看所属是否可以对应为定义或者匹配下一个规则
- 确定结束或者用下一个规则处理
如此循环,直到所有式子处理结束
语法分析
语法分析的地位:是编译程序的核心部分
语法分析程序的处理:识别由词法分析得出的单词序列是否是给定文法的句子。
语法分析的理论基础:上下文无关文法和下推自动机
语法分析的方式:
- 自上而下语法分析反复使用不同产生式进行推导以谋求与输入符号串相匹配
- 自下而上语法分析对输入符号串寻找不同产生式进行归约直到文法开始符号。
这里所说的输入符号指词法分析所识别的单词。
下推自动机
下推自动机模型图(PDA)
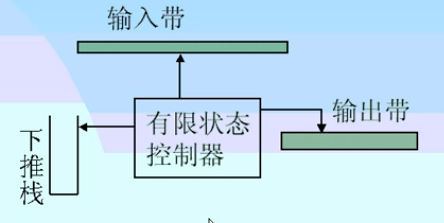
- PDA和FA的模型相比,多了一个下推栈。
- PDA的动作由三个因素来决定:当前状态、读头所指向符号、下推栈栈顶符号。
- 一个输入串能被PDA所接受,仅当输入串读完,下推栈变空;或输入串读完,控制器到达某些终态
- 正规文法和有限自动机仅适合于描述和识别高级语言的各类单词,语句可用上下文无关文法来描述,而下推自动机又恰好能识别上下文无关文法所能描述的语言,因此上下文无关文法及其对应的下推自动机就成为编译技术中语法分析的理论基础。


自上而下分析法
定义:从文法的开始符号开始,反复使用不同产生式进行推导以谋求与输入符号串相匹配。
此处的输入符号串是指词法分析结果的一串二元式
一般方法:
-
试探法:带回溯的自上而下分析法。
-
缺陷:
如果文法存在左递归,语法分析会无限循环下去。(分为直接和间接左递归,可以消除左递归)
若产生式存在多个候选式,选择哪个进行推导完全是盲目的。(预测与提左因子)
回溯会引起时间和空间的大量消耗。(可以消除回溯,非盲目选择即可消除回溯)
如果被识别的语句是错的,算法无法指出错误的确 切位置。
-
带预测分析的PDA
在PDA中加入预测分析之后,可以消除自上而下分析中出现回溯的现象。此时PDA可以改造为:
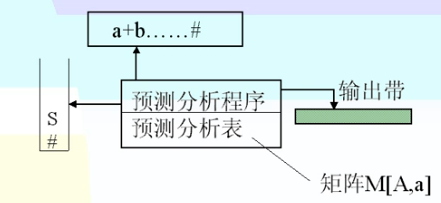
- 改造后,整个分析过程都在预测分析程序控制下工作。
- 预测分析程序用了一个预测分析表,它是预测分析程序分析时的主要依据。
预测分析表是一矩阵M[A,a],其中行标A是非终结符,列标a是终结符或串结束符;矩阵元素M[A,a]是存放A的一个候选式,指出当前栈顶符号为A且面临读入符号为a时应选的候选式;或者存放“出错标志”,指出A不该面临读入符号a。