本章是 D4n的Java安全入门 第一篇,望大佬指正,小白避坑
测试用Java版本(17.0.6)
Java反序列化
什么是反序列化
借用一下大佬的描述:
Java描述的是一个‘世界’,程序运行开始时,这个‘世界’也开始运作,但‘世界’中的对象不是一成不变的,它的属性会随着程序的运行而改变。 但很多情况下,我们需要保存某一刻某个对象的信息,来进行一些操作。比如利用反序列化将程序运行的对象状态以二进制形式储存与文件系统中,然后可以在另一个程序中对序列化后的对象状态数据进行反序列化恢复对象。可以有效地实现多平台之间的通信、对象持久化存储。
序列化与反序列化是让Java对象脱离Java运行环境的一种手段,可以有效的实现多平台之间的通信、对象持久化存储。
用自己的话说就是,如果需要传输一个对象(或是一段数据)给目标(途径可以是网络,进程间等任何可以传输数据的地方,目标可以是客户端,子进程,线程等)需要将对象的一些或者所有信息以一种格式传输给目标,比如常见的JSON、XML、YAML格式,就是将一些数据格式化为相应标准格式的例子
这种将数据格式标准化的过程就可以称之为序列化,而对应的,目标接收到这种格式化数据之后,将对象或者数据还原成原本或者需要的样子就称为反序列化。
在Java中想要序列化一个对象,需要同时满足两个条件:
- 该类必须实现 java.io.Serializable 接口。
- 该类的所有属性必须是可序列化的。如果有一个属性不是可序列化的,则该属性必须注明是短暂的。
只有实现了Serializable或Externalizable接口的类的对象才能被序列化,否则抛出异常。
注:Externalizable 是继承了Serializable的抽象类
所以你想知道一个Java标准类是否是可序列化的,可以查看他的类描述,看是否实现了java.io.Serializable接口
为什么要序列化
对象不只是存储在内存中,它还需要在传输网络中进行传输,并且保存起来之后下次再加载出来,这时候就需要序列化技术。
Java的序列化技术就是把对象转换成一串由二进制字节组成的数组,然后将这二进制数据保存在磁盘或传输网络。而后需要用到这对象时,磁盘或者网络接收者可以通过反序列化得到此对象,达到对象持久化的目的。
反序列化漏洞来源
-
开发失误
- 开发人员并没有重写
ObjectInputStream类的resolveClass方法,或者重写过但是过滤不严格就会导致反序列化漏洞
- 开发人员并没有重写
-
使用了不安全的基础库
- 很大比例的反序列化漏洞是因使用了不安全的基础库而产生的,一般优秀的Java开发人员会按照安全编程规范进行编程,并且一些成熟的Java框架
Spring MVC、Struts2等会有相应的防范机制,如果只是开发失误的话,能造成的反序列化漏洞很少 但使用不安全的基础库则不一样
- 很大比例的反序列化漏洞是因使用了不安全的基础库而产生的,一般优秀的Java开发人员会按照安全编程规范进行编程,并且一些成熟的Java框架
2015年由黑客Gabriel Lawrence和Chris Frohoff发现的
Apache Commons Collections类库直接影响了WebLogic、WebSphere、JBoss、Jenkins、OpenNMS等大型框架。直到今天该漏洞的影响仍未消散。 存在危险的基础库:
1 2 3 4 5 6 7 8 9 10 11 12commons-fileupload 1.3.1 commons-io 2.4 commons-collections 3.1 commons-logging 1.2 commons-beanutils 1.9.2 org.slf4j:slf4j-api 1.7.21 com.mchange:mchange-commons-java 0.2.11 org.apache.commons:commons-collections 4.0 com.mchange:c3p0 0.9.5.2 org.beanshell:bsh 2.0b5 org.codehaus.groovy:groovy 2.3.9 org.springframework:spring-aop 4.1.4.RELEASE某反序列化防护软件便是通过禁用以下类的反序列化来保护程序:
1 2 3 4 5 6 7 8'org.apache.commons.collections.functors.InvokerTransformer', 'org.apache.commons.collections.functors.InstantiateTransformer', 'org.apache.commons.collections4.functors.InvokerTransformer', 'org.apache.commons.collections4.functors.InstantiateTransformer', 'org.codehaus.groovy.runtime.ConvertedClosure', 'org.codehaus.groovy.runtime.MethodClosure', 'org.springframework.beans.factory.ObjectFactory', 'xalan.internal.xsltc.trax.TemplatesImpl'
基础库中的调用流程一般都比较复杂,不会如同接下来给出的测试用例一般简单,涉及到POP链,反射,泛型等知识
如何序列化与反序列化
JDK类库提供的序列化API
- java.io.ObjectOutputStream:表示对象输出流 它的writeObject(Object obj)方法可以对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
- java.io.ObjectInputStream:表示对象输入流 它的readObject()方法从源输入流中读取字节序列,再把它们反序列化成为一个对象,并将其返回。
Java对象序列化与反序列化的调用流程
方法一:
若Student类仅仅实现了Serializable接口,则可以按照以下方式进行序列化和反序列化。 ObjectOutputStream采用默认的序列化方式,对Student对象的非transient的实例变量进行序列化。 ObjcetInputStream采用默认的反序列化方式,对对Student对象的非transient的实例变量进行反序列化。
方法二:
若Student类仅仅实现了Serializable接口,并且还定义了readObject(ObjectInputStream in)和writeObject(ObjectOutputSteam out), ObjectOutputStream调用Student对象的writeObject(ObjectOutputStream out)的方法进行序列化。 ObjectInputStream会调用Student对象的readObject(ObjectInputStream in)的方法进行反序列化。
方法三:
若Student类实现了Externalnalizable接口,且Student类必须实现readExternal(ObjectInput in)和writeExternal(ObjectOutput out)方法,则按照以下方式进行序列化与反序列化。 ObjectOutputStream调用Student对象的writeExternal(ObjectOutput out))的方法进行序列化。 ObjectInputStream会调用Student对象的readExternal(ObjectInput in)的方法进行反序列化。
尝试序列化
先写一个待反序列化的类:
|
|
然后再写一个序列化和反序列化测试类:
|
|
运行后,Employee对象的序列化数据就存储到了Serialize.txt中,我们打开看一下(使用二进制查看器)
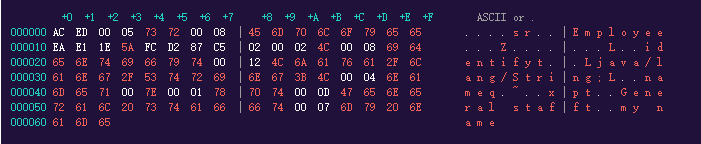
可以依稀看见:类名,属性名称,属性类型,以及属性对应的值
值得注意的是:大部分的反序列化数据均是以AC ED 00 05 开头的
反序列化操作就是从字节流中提取对象:
|
|
运行后可以发现Employee的数据已经获取到了目标程序中对象e里
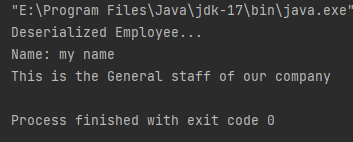
上诉就是一个完整的序列化周期,中间使用文件暂时作为了传输介质,其实实际应用中的序列化无非就是传输的方式和传输机制稍微复杂一点
总结序列化具体步骤
从上面的可以看出对象的序列化步骤是:
创建一个对象输出流,它可以包装一个其它类型的目标输出流,如文件输出流:
ObjectOutputStream out = new ObjectOutputStream(new fileOutputStream(“D:\\objectfile.obj”));通过对象输出流的writeObject()方法写对象:
1 2out.writeObject(“Hello”); out.writeObject(new Date());
对象的反序列化步骤是:
创建一个对象输入流,它可以包装一个其它类型输入流,如文件输入流:
ObjectInputStream in = new ObjectInputStream(new fileInputStream(“D:\\objectfile.obj”));通过对象输出流的writeObject()方法写对象:
1 2String obj1 = (String)in.readObject(); Date obj2 = (Date)in.readObject();
序列化与反序列化的必要条件
- 必须是同包,同名。
- serialVersionUID必须一致。有时候两个类的属性稍微不一致的时候,可以通过将此属性写死值,实现序列化和反序列化。
序列化中涉及细节
serialVersionUID
版本控制
Java的序列化机制是通过在运行时判断类的 serialVersionUID 来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致,代码中设置 serialVersionUID 可以在类中添加 private static final long serialVersionUID = 1L
当实现java.io.Serializable接口的实体(类)没有显式地定义一个名为serialVersionUID,类型为long的变量时,Java序列化机制会根据编译的class自动生成一个serialVersionUID作序列化版本比较用,这种情况下,只有同一次编译生成的class才会生成相同的serialVersionUID
如果我们不希望通过编译来强制划分软件版本,即实现序列化接口的实体能够兼容先前版本,未作更改的类,就需要显式地定义一个名为serialVersionUID,类型为long的变量,不修改这个变量值的序列化实体都可以相互进行串行化和反串行化。
常见场景
问题出现场景:两个客户端 A 和 B 试图通过网络传递对象数据,A 端将对象 C 序列化为二进制数据再传给 B,B 反序列化得到 C。 问题:C 对象的全类路径假设为 com.inout.Test,在 A 和 B 端都有这么一个类文件,功能代码完全一致。也都实现了 Serializable 接口,但是反序列化时总是提示不成功。 解决:统一serialVersionUID的值
虽然两个类的功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化。
serialVersionUID 使用场景
序列化存储规则
- 将同一对象序列化并两次写入同一文件时
Java 序列化机制为了节省磁盘空间,具有特定的存储规则,当写入文件的为同一对象时,并不会再将对象的内容进行存储,而只是再次存储一份引用,文件只会增加小小的几个字节,这几个字节的存储空间就是新增引用和一些控制信息的空间。反序列化时,恢复引用关系,使得反序列化的 e1 和 e2 指向唯一的对象,二者相等,为引用关系,该存储规则极大的节省了存储空间。
- 将对象序列化后写入文件,修改对象参数值后再次序列化后写入同一文件时
第一次写入对象以后,第二次再试图写的时候,虚拟机根据引用关系知道已经有一个相同对象已经写入文件,因此只保存第二次写的引用,所以读取时,都是第一次保存的对象。读者在使用一个文件多次 writeObject 需要特别注意这个问题。
更多细节
关于 静态变量序列化 ,父类的序列化与 Transient 关键字,对敏感字段加密,移步链接3
初识反序列化漏洞
Java反序列化时,会调用readObject方法就行反序列化操作,当readObject方法书写不当时就会引发漏洞
有时也会使用readUnshared()方法来读取对象,readUnshared()不允许后续的readObject和readUnshared调用引用这次调用反序列化得到的对象,而readObject读取的对象可以
大佬给的例子:
|
|

能够成功执行到Runtime.getRuntime().exec("calc.exe");
对反序列化的疑问与分析
关于大佬的代码我有几个疑问:
-
Runtime.getRuntime().exec("calc.exe");只能够控制弹出一个计算器,我能不能使用一个字符串变量代替(PHP反序列化的经验告诉我应该是可行的),进而轻松改变将要执行的命令? -
UnsafeClass0 的 readObject 是何时被执行的,是被谁调用的(因为当我查看下图readObject执行时的源码时
 跳转的是ObjectInputStream类的readObject
跳转的是ObjectInputStream类的readObject
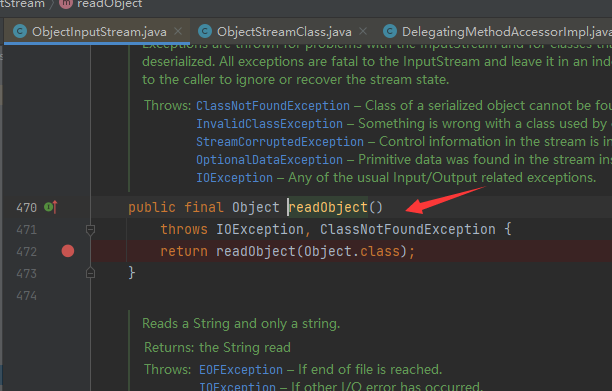
那么是什么时候调用的UnsafeClass0的readObject呢?(强转类型的时候吗?)
第一个问题
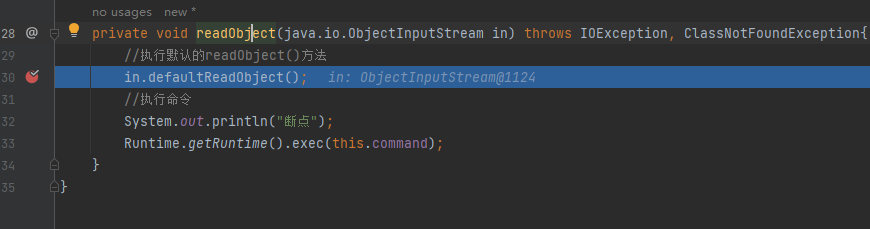
关于第一个问题,只需要将断点打到Runtime.getRuntime().exec("calc.exe");,然后观察变量就不难看出可以使用this.command打到我想要的效果,所以修改代码为
|
|
此时只需要控制 Unsafe 对象的 command 属性值即可执行不同命令
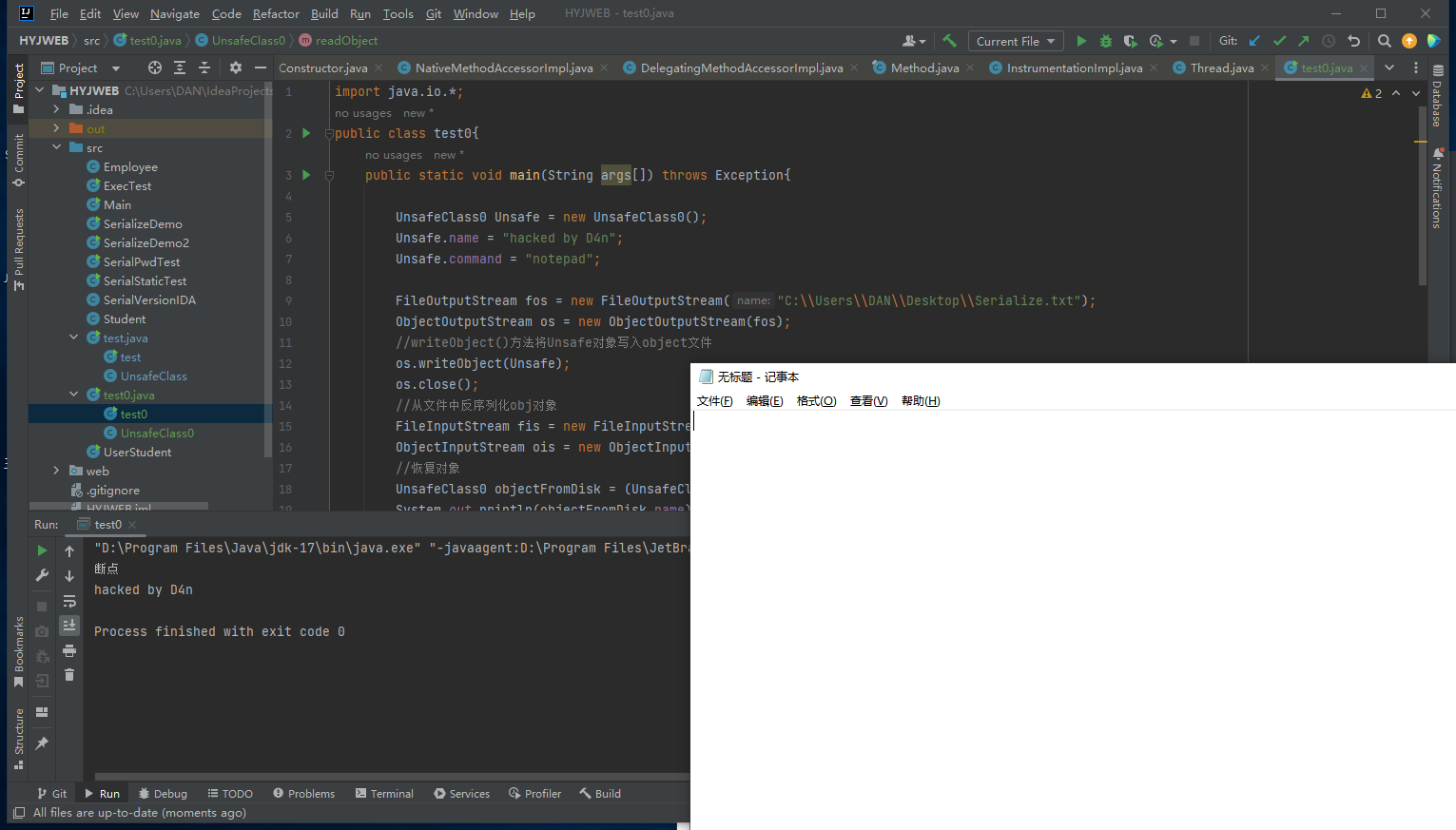
但是在分析第一个问题的时候,刚进入 UnsafeClass0的readObject()方法的时候,this还没有被赋值
 再步过
再步过in.defaultReadObject();的时候,this 的变量值就被赋值成了我们设置的样子:
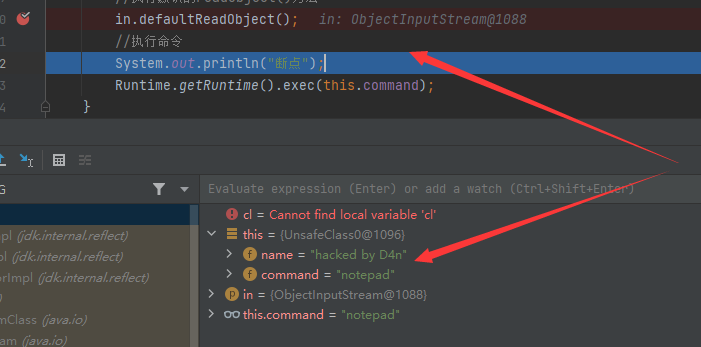
所以我想跟进一下,关于this变量是什么时候怎么样被赋值的,所以应该着重分析in.defaultReadObject();干了哪些事,并且在此之前,其他相关反序列化代码做的事只是创建好对象,开辟好空间,没有赋值操作(猜测)
新问题:关于this变量是什么时候怎么样被赋值的(序列化字符串是怎么一步一步变成对象的)
让我们进入in.defaultReadObject();看看
没法直接步入,所以要先 ctrl + B 进入源码后再打断点
贴个源码:
|
|
其中第一句赋值完成后就可以看到

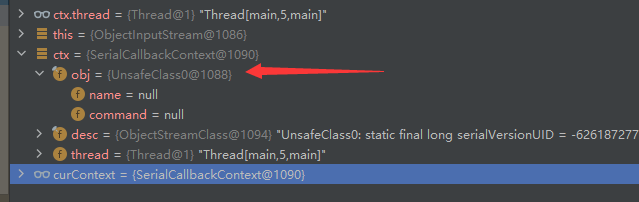
ctx中已经存放好了 UnsafeClass0 类的未初始化对象(实际从地址来看就是在in.defaultReadObject();调用时的"this变量",为了方便称呼,我称之为UnsafeClass0--this
之后
-
Object curObj = ctx.getObj();将this地址值赋值给 curObj,即 curObj 是UnsafeClass0--this的引用 -
ObjectStreamClass curDesc = ctx.getDesc();将对象流赋值给curDesc查看 curDesc 发现

猜测这里存放的是对象属性以及对应值,粗略查看没有找到具体数据,过
bin.setBlockDataMode(false);BlockDataInputStream
这句的粗略理解就是一个流程控制,暂时无关我需要分析的问题,过
问题1-2:关于this变量是什么时候怎么样被赋值的
FieldValues values = new FieldValues(curDesc, true);
这句执行之后 curObj暂时没有发生变化
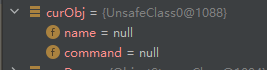
所以先不去查看FieldValues在做什么事情,根据构造的传参猜测大致是对 类描述进行处理
接下来进入 if判断

( curObj 不为空 )
执行完values.defaultSetFieldValues(curObj);之后,curObj的值就被设置好了,果然使用到了 FieldValues类的对象values,跟进一下values.defaultSetFieldValues(curObj);
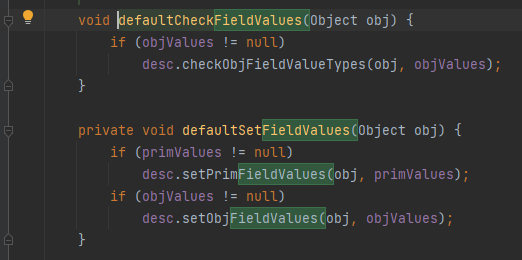
defaultSetFieldValues()第一个IF判断false,第二个判断Ture,将要修改的对象Obj 传入desc.setObjFieldValues(obj, objValues);,跟进前看看objValues是个什么东西
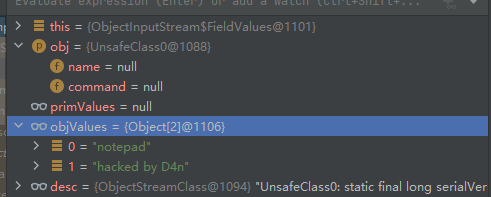
发现值已经被设置好了,那setObjFieldValues()做的可能只是复制objValues里的值给Obj,此时UnsafeClass0--this就已经改变了
新问题:objValues 是什么时候赋值的呢
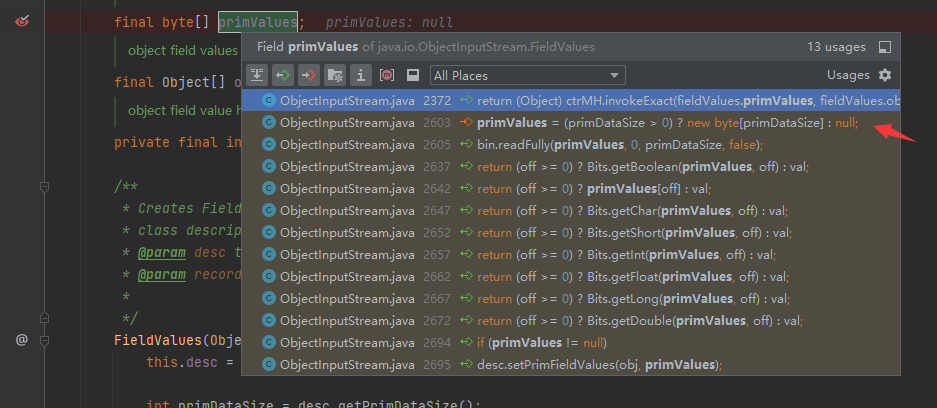
跟进看一下

这里就是在往objValues里写东西了,看看readObject0如何解析的(f.isUnshared()返回一个布尔值)
经历一系列类似流程控制的东西,最后来到了这

先看看 readString 在干嘛:
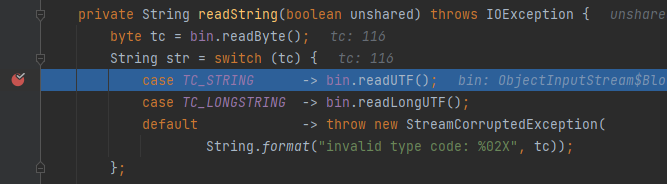
先完整执行一遍,发现路过那条switch语句的时候,str就能被赋值为序列化字符串里的关键字

说明readUTF是在从序列化字符串中提取数据,看看 bin 是个什么东西
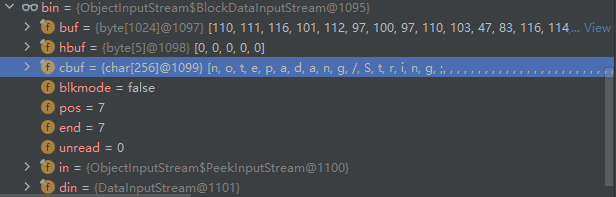
bin里是已经处理好的序列化字符串碎片,那么是哪个函数在处理整个序列化字符串呢?(找到给bin赋值的语句)
直接看看不出什么端倪,看来只有跟着断点走一次
走一次,没有找到给bin.cbuf赋值的地方,但是有意外收获:
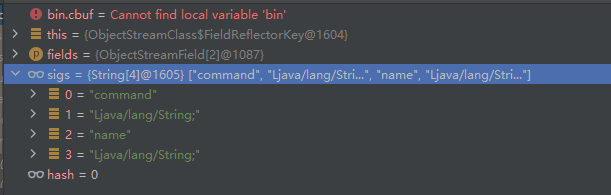
这不就是妥妥的咱要找的东西吗,sigs的来源找到了,怎么赋值给bin.cbuf就暂时不深究了(毕竟其实很想看到的就是如何从序列化中提取出之前写入的序列化数据)
这里的代码是这样的:
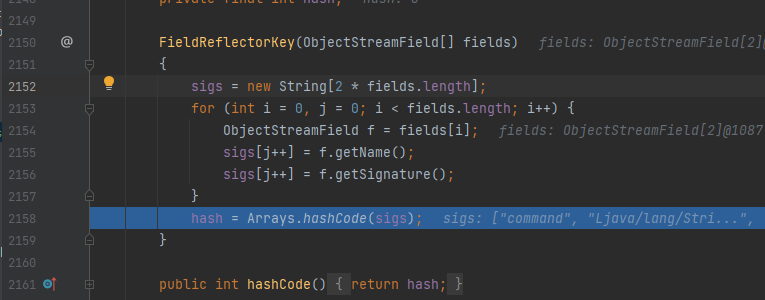
查看一下这个sigs能在哪些地方被赋值
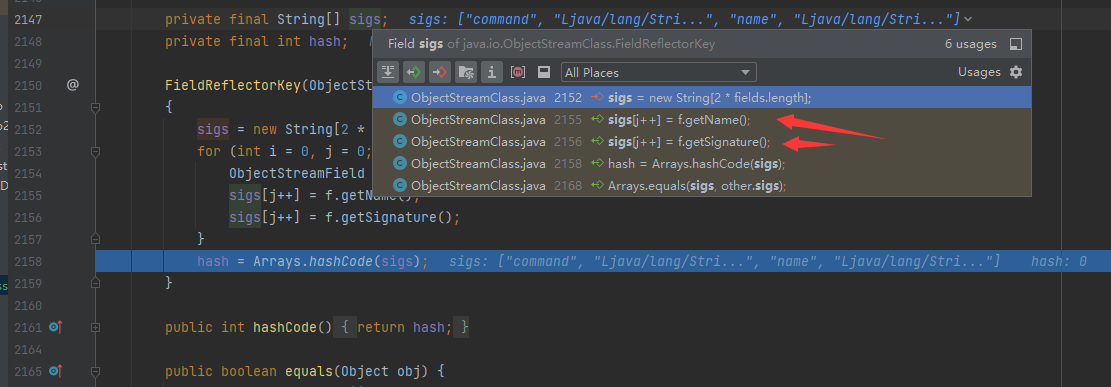
看来就只有sigs[j++] = f.getName();sigs[j++] = f.getSignature();这两个地方,康康f.getName()和f.getSignature()在干嘛
,,,,他没干嘛,所以看看 f 怎么来的 (可恶,对 get set 类函数还是不够敏感,但是也算严谨,,,,)
ObjectStreamField f = fields[i];,所以得看看fields是怎么来的 Field类说明
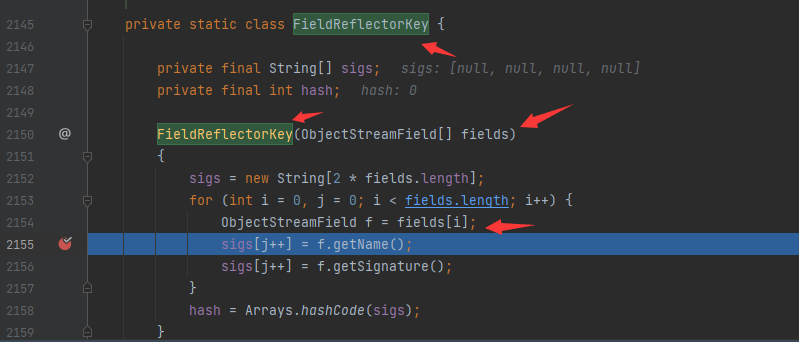
这里的fields是直接传参进来的,而且这里是FieldReflectorKey类的构造函数,康康谁在new呢?

这里的fields哪来的?
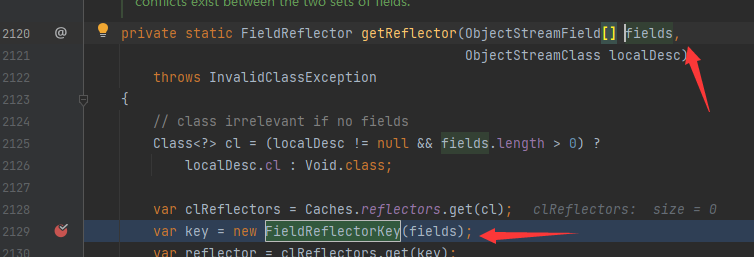
这里的fields也是传参,再跟!

这里发现给fields赋值的地方有些多,重新debug看看
多次尝试,发现赋值的地方在:

再路过就已经处理好啦,跟进:

这步赋值,跟进:
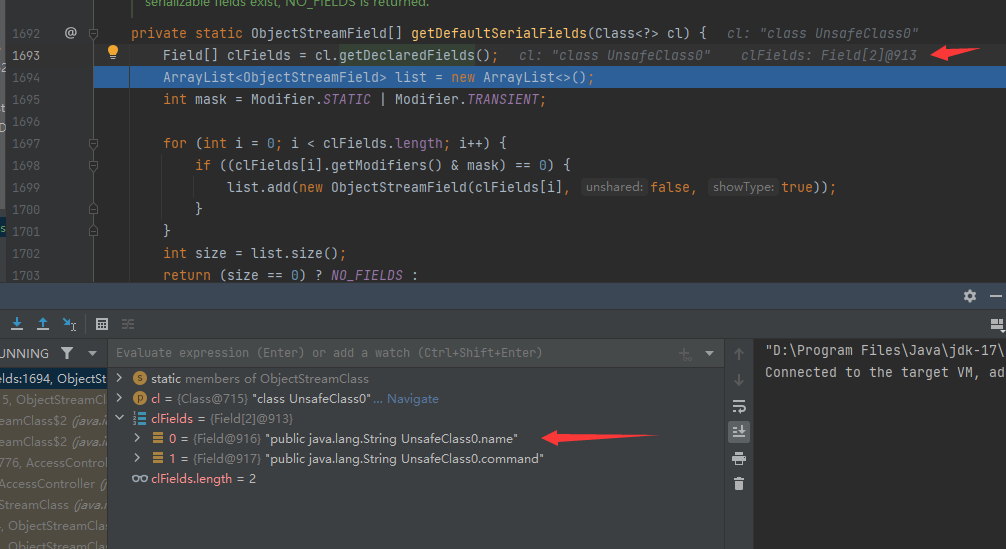
这步又是已经被处理好了(怎么这么多检测)重新在Field[] clFields = cl.getDeclaredFields();处打个断点,重新看看
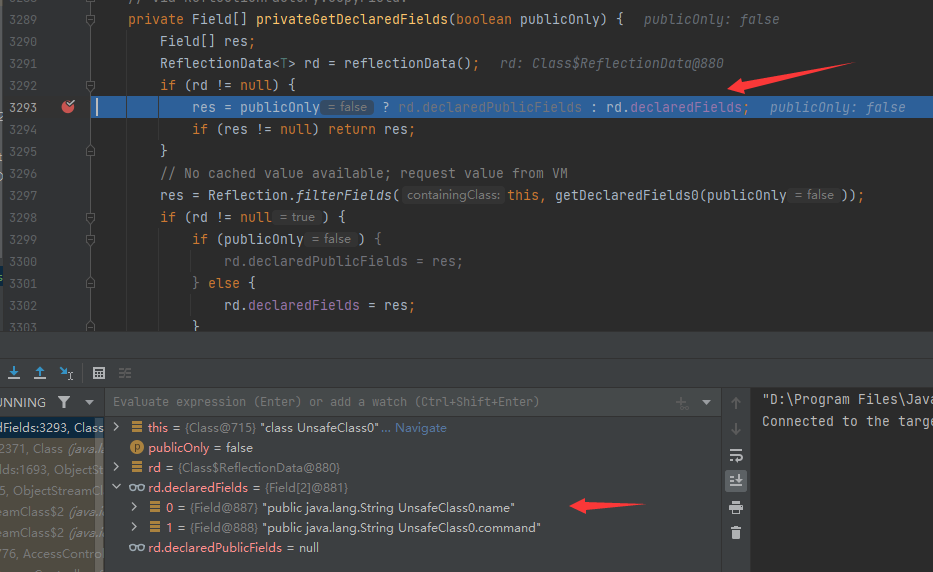
又是被处理好的,重新跟踪rd
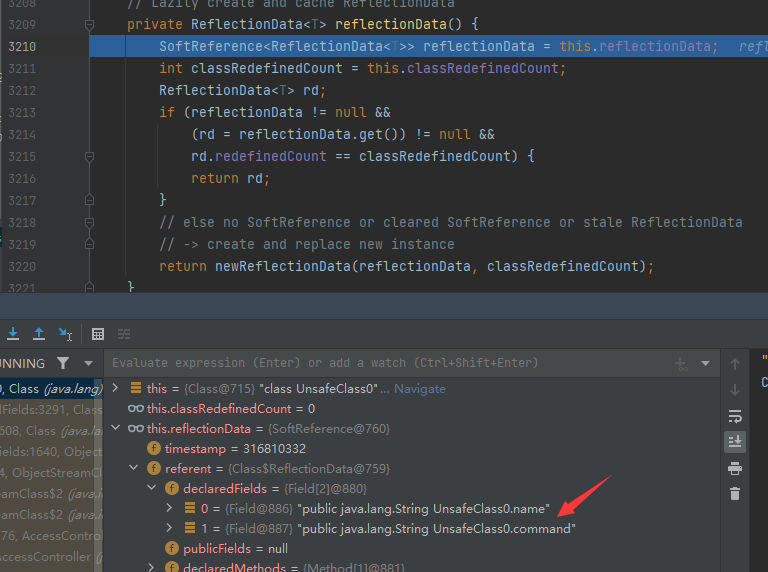
又,调用的时候已经有了,,,经过反复调试,终于找到一个像是最初处理的函数

但是已经没有办法追踪了,getDeclaredFields0(publicOnly)粗略理解:
getDeclaredFields0() 是 Java 中 Class 类的一个本地方法,实际上是使用 C 或 C++ 等本地语言编写的。本地方法是 Java 中与底层操作系统和硬件交互的一种机制,可以让 Java 程序能够调用底层操作系统提供的本地功能和资源。 Java 语言本身并不支持底层操作系统和硬件的访问,因此需要使用本地方法来扩展 Java 的能力。本地方法通常由本地库(native library)实现,本地库是一个动态链接库(.dll 或 .so 文件),其中包含了本地方法的实现。在 Java 中,可以使用 System.loadLibrary() 或 System.load() 方法来加载本地库,从而使 Java 程序能够调用本地方法。 在 Class 类中,getDeclaredFields0() 方法是使用本地语言编写的本地方法,它实现了获取一个类中声明的所有成员变量的功能。当 Java 程序调用 getDeclaredFields() 方法时,实际上是调用了 getDeclaredFields0() 方法的 Java 封装,而这个封装方法会通过 JNI(Java Native Interface)机制来调用本地方法的实现。
但是getDeclaredFields0(publicOnly)只是获得了类里声明的成员变量,并没有给其赋值,具体的值是什么时候抽取出来的?
重新调整思路,一路debug寻找,找到了readUTFBody:
|
|
粗略理解一下:
readUTFBody,它的作用是从输入流中读取指定长度的UTF-8字符串,并将其转换为Java的String类型返回。
具体来说,代码的主要逻辑如下:
根据指定的
utflen(表示UTF-8编码的字节数)创建一个StringBuilder对象sbuf,作为存储解码后字符串的缓冲区。如果utflen在 0 和Integer.MAX_VALUE之间,则设置sbuf的初始容量为utflen和 0xFFFF 之间的较小值,以提高性能。如果当前输入流不处于块模式,则将输入流的
pos和end分别设置为0,表示当前没有读取任何数据。进入一个while循环,循环条件是utflen大于0,即还需要继续读取字符串。
在每次循环中,根据输入流的
pos和end计算当前可用的字节数avail。如果avail大于等于3,或者与utflen相等,则调用readUTFSpan()方法读取一段连续的字节,并将其解码成字符串,将解码后的字符串追加到sbuf中,并将已经读取的字节数从utflen中减去。如果
avail小于3且不等于utflen,则分两种情况处理:
- 如果当前输入流处于块模式,则说明接近块边界,便逐个字节地读取剩余字节,调用readUTFChar函数读取一个字符,将解码后的字符追加到
sbuf中,并将已经读取的字节数从utflen中减去。- 如果当前输入流不处于块模式,则手动移动剩余字节到缓冲区的开头,重新填充缓冲区,将
pos和end分别设置为0和新的可读取字节数,然后继续循环读取数据。在while循环结束后,返回
sbuf缓冲区中存储的解码后的字符串,即读取的UTF-8字符串。需要注意的是,在读取字节和解码字符串的过程中,如果遇到任何错误(如读取字节失败、解码失败等),则会抛出
IOException或UTFDataFormatException异常。
简单来说就是把字节流转换成字符串的函数,字节流是从buff变量里面读取的,buff是什么时候赋值的呢 in.readFully()
所以完整序列化数据到对象的过程:
in.readFully()读入指定位置和字数的字节到buff,readUTFBody()和readUTFSpan()控制buff字节流的同时读出里面的属性名与其对应属性,返回到ObjectStreamClass里组装到fields里,然后返回值一路返回到ObjectInputStream类里,这之前都是为了生成对类的细节描述“des”:类名,属性名,属性类型,做好了对象的框架后最后再ObjectStreamClass里对类进行了实例化
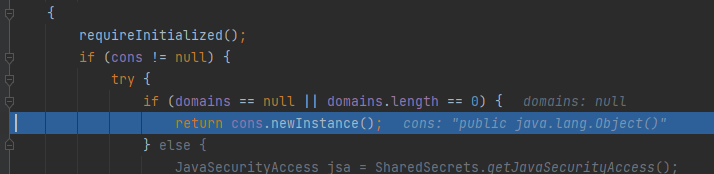
调用的也是反射类的实例函数:

最后在ObjectInputStream里obj接收到了返回的实例化好的空的UnsafeClass0对象
此时再次调试发现回到了我们定义的类里面
所以可以确定了,在执行UnsafeClass0.readObject中的in.defaultReadObject();之前,都只是在初始化一个UnsafeClass0类的实例化对象,此时再进入defaultReadObject进行值的赋
defultReadObject做的是就是拿到当前需要赋值的ObjcurObj和当前处理好的对该Obj的描述curDesc然后在创建FieldValuse对象初始化
这次初始化也是通过调用

readUTF等一系列方法对序列化字节进行处理得到具体值
通过curDesc拿到该赋的具体值给curObj赋值,即可完成反序列化
第二个问题
UnsafeClass0 的 readObject 是有参数的,所以UnsafeClass0 objectFromDisk = (UnsafeClass0)ois.readObject();肯定不是直接调用 UnsafeClass0 中的 readObject,那是谁调用的呢?可以通过函数栈观察
调用情况使用 => 表示
main => ObjectInputStream.readObject => ObjectInputStream.readObject0 => ObjectInputStream.readOrdinaryObject => ObjectInputStream.readSerialData => ObjectStreamClass.invokeReadObject => Method.invoke => 然后一堆看不懂的 => UnsafeClass0.readObject
看到熟悉的 Method.invoke了吗,(好吧其实也不是很熟)Java也是通过反射来调用 UnsafeClass0.readObject
至此,反序列化的初步理解就告一段落了
POP链
POP(Property-Oriented Programming)直译的话就是面向属性编程,如果学过二进制的话就可以类比一下ROP。 POP 链的构造则是寻找程序当前环境中已经定义了或者能够动态加载的对象中的属性(函数方法),将一些可能的调用组合在一起形成一个完整的、具有目的性的操作。
作者个人理解:从可控的输入点到最终的代码执行点一般不是直达的,此时需要精心构造或者寻找一些能够在不同对象,方法之间跳转的跳板函数或者跳板对象。且这些跳板本身可能并不是用作跳板用途,有时候的跳板可能只是利用了相关函数的设计机制(例如PHP中访问一个对象不存在的方法时会被调用该对象的__class__魔术方法)
在之后的文章中,会深刻的领悟到POP的精髓
反射
要知道什么是反射,首先就要知道"正射"是怎么样的
一般情况下,我们使用某个类前,我们是知道这个类的类名的,比如实例化对象的时候
|
|
类似这种知道要初始化类的类名,并将其写死在代码中,运行时无法更改的,就可以称之为正射
反射的话就是和正射反着来,程序运行起来之前,我并不知道我需要初始化类的类名叫什么,所以我无法在代码中写死
举一个不恰当但是很合适的需求:我需要使用Java写一个程序,在其运行期间,我每输入一个类的名字,Java程序就帮我实例化好这个类对象,将其序列化成字节流,并创建写入一个文件,路径和我的工作路径相同,文件名就是我输入的类的名字,其中对象的整形属性按照变量名的字母数赋值,其他类型的属性赋值为 Null
如果没有在其运行期间这个前提条件的话,实现这个需求我们可以手动 new 出对象来,然后数出变量名字母数,然后序列化好放入文件中
反射是Java的特征之一,是一种间接操作目标对象的机制,核心是JVM在运行状态的时候才动态加载类,对于任意一个类都能够知道这个类所有的属性和方法,并且对于任意一个对象,都能够调用它的方法/访问属性。这种动态获取信息以及动态调用对象方法的功能成为Java语言的反射机制。通过使用反射我们不仅可以获取到任何类的成员方法(Methods)、成员变量(Fields)、构造方法(Constructors)等信息,还可以动态创建Java类实例、调用任意的类方法、修改任意的类成员变量值等。
但是在运行期间的话,只能使用到反射了(举例到此为止,接下来的代码不解决上诉需求)
我们可以使用 JDK 提供的反射 API 进行反射调用
|
|
这两段代码的能实现相同的作用,但是第二段代码获取类实例化对象时,类名是通过字符串获取的
反射就是在运行时才知道要操作的类是什么,并且可以在运行时获取类的完整构造,并调用对应的方法。
接下来先看看使用反射我们能简单干些什么,怎么使用反射
获取Class对象
在反射中,要获取一个类或调用一个类的方法,我们首先需要获取到该类的 Class 对象。
有三种方法
第一种,使用 Class.forName 静态方法。当你知道该类的全路径名时,你可以使用该方法获取 Class 类对象。
Class clz = Class.forName("java.lang.String");
第二种,使用 .class 方法。
这种方法只适合在编译前就知道操作的 Class 名
Class clz = String.class;
第三种,使用类对象的 getClass() 方法
String str = new String("Hello");Class clz = str.getClass();
- 这三种获取CLass类方式中,我们一般使用第一种通过
Class.forName方法去动态加载类。且使用 forName 就不需要import导入其他类,可以加载我们任意的类。 - 使用第二种
类.class属性,需要导入类的包,依赖性太强,在大型项目中容易抛出编译错误; - 使用第三种
实例化对象的getClass()方法,需要本身创建一个对象,本身就没有了使用反射机制意义。
所以我们在获取class对象中,一般使用第一种Class.forName方法去获取。
获取成员变量Field
获取成员变量Field位于java.lang.reflect.Field包中
Field[] getFields() :获取所有public修饰的成员变量
Field[] getDeclaredFields() 获取所有的成员变量,不考虑修饰符
Field getField(String name) 获取指定名称的 public修饰的成员变量
Field getDeclaredField(String name) 获取指定的成员变量
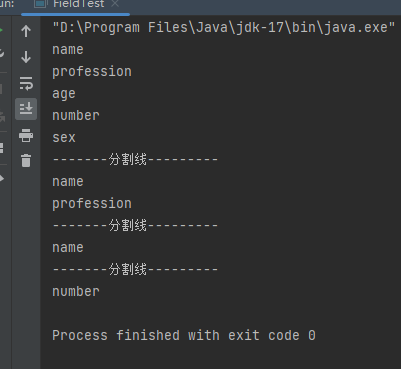
用一个例子理解:
|
|
获取成员方法Method
Method getMethod(String name, 类… parameterTypes) //返回该类所声明的public方法
Method getDeclaredMethod(String name, 类… parameterTypes) //返回该类所声明的所有方法
//第一个参数获取该方法的名字,第二个参数获取标识该方法的参数类型
Method[] getMethods() //获取所有的public方法,包括类自身声明的public方法,父类中的public方法、实现的接口方法
Method[] getDeclaredMethods() // 获取该类中的所有方法
|
|
运行结果:
|
|
获取构造函数
Constructor[] getConstructors() :只返回public构造函数
Constructor[] getDeclaredConstructors() :返回所有构造函数
Constructor<> getConstructor(类… parameterTypes) : 匹配和参数配型相符的public构造函数
Constructor<> getDeclaredConstructor(类… parameterTypes) : 匹配和参数配型相符的构造函数
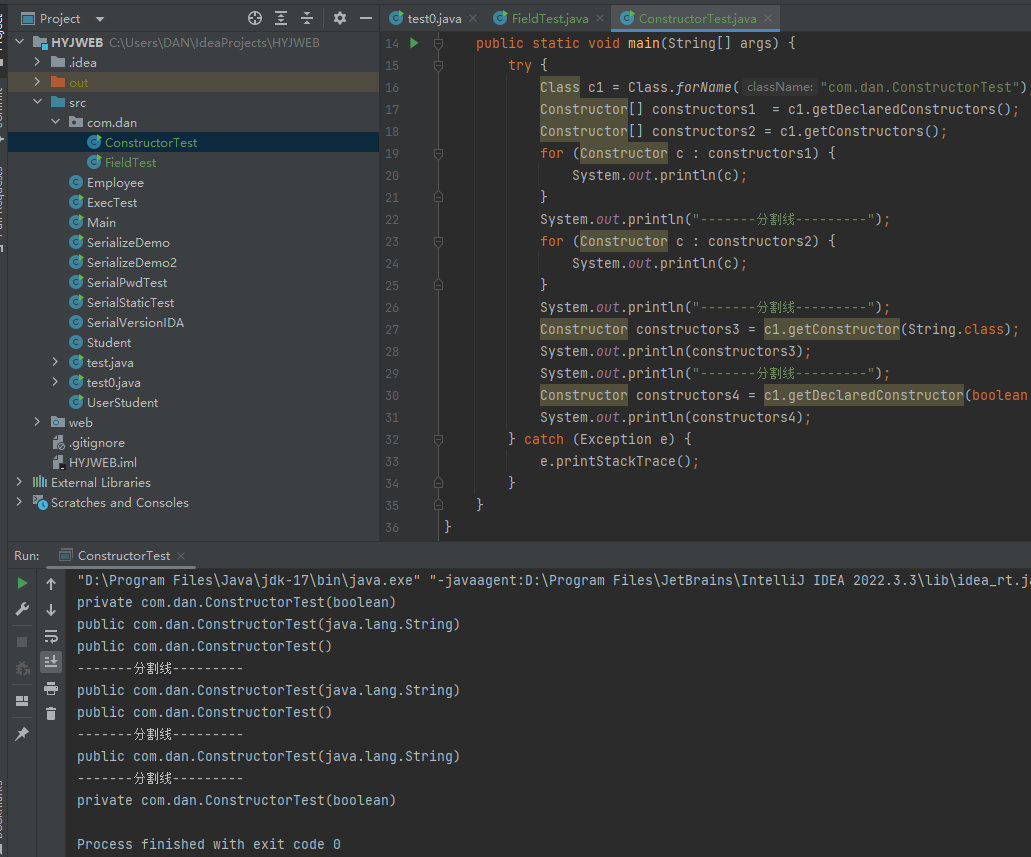
例子总比文字好理解:
|
|
获取对象
- 先获取类的 Class 对象实例
Class clz = Class.forName("com.api.Apple");
- 根据 Class 对象实例获取 Constructor 函数
Constructor appleConstructor = clz.getConstructor();
- 使用 Constructor 对象的 newInstance 方法获取反射类对象
Apple appleObj = (Apple)appleConstructor.newInstance();
或者也可以使用 Class对象 的newInstance()方法来进行创建类对象
Apple appleObj = (Apple)clz.newInstance();
区别在于通过 Constructor 对象创建类对象可以选择特定构造方法,而通过 Class 对象则只能使用默认的无参数构造方法。下面的代码是使用一个有参数的构造方法进行了类对象的初始化
1 2 3Class clz = Apple.class; Constructor constructor = clz.getConstructor(String.class, int.class); Apple apple = (Apple)constructor.newInstance("红富士", 15);
常用的是如下实例:
|
|
调用方法步骤
获取对象使用的是 newInstance(),那么调用函数使用的就是invoke()
invoke方法位于java.lang.reflect.Method类中,用于执行某个的对象的目标方法。一般会和getMethod方法配合进行调用。invoke使用小Tips:
public Object invoke(Object obj, Object... args)obj:从中调用底层方法的对象,必须是实例化对象 如果调用的这个方法是普通方法**,**第一个参数就是目标类实例化对象; 如果调用的这个方法是静态方法,第一个参数就是Class对象;
args: 用于方法的调用,是一个object的数组,参数有可能是多个
基本步骤
- 获取类的 Class 对象实例
Class clz = Class.forName("com.api.Apple");
- 获取方法的 Method 对象
Method setPriceMethod = clz.getMethod("setPrice", int.class);
- 利用 Method 对象的 invoke 方法调用方法(本例子需要提前准备实例化对象)
setPriceMethod.invoke(appleObj, 14);
调用方法完整小例子:
|
|
上面讲述了反射机制流程概念和基本使用方法,从Class对象获取,到获取成员变量、成员方法和构造函数,接着是newInstance创建类对象和invoke方法,最后是一个简单反射例子的组成。
回归到漏洞学习中,看看如何使用java反射中如何获取Runtime类来命令执行
|
|
上面的例子会报错:

但我们发现了使用newInstance产生了报错的话,而往往其可能是以下原因未能实现。
1、使用的类没有无参构造函数 2、使用的类构造函数是私有的
构造函数私有化
上例报错是因为构造函数私有,构造函数私有有如下作用:
-
单例模式
单例模式主要有3个特点:
-
类的内部包括一个类的实例,并且为static类型
-
构造函数为私有
-
通过提供一个获取实例的方法,比如getInstance,该方法也为static类型。 调用的时候,我们可以通过某些特殊静态函数例如
Singleton instance = Singleton.getInstance();来获得实例化的对象
单例模式的使用: 很多时候,我们只需要一个对象就可以了,不希望用户来构造对象,比如线程池,驱动,显示器等。如果把构造函数私有,那么很多程序都可以得到其实例,将会带来混乱。
-
-
防止实例化
在Java的工具类中,有很多就是利用这种方法
一个工具类Utils,里面含有很多静态函数或者静态变量,由于静态的原因,我们完全可以通过类名来访问,这样,我们就没有必要实例化它们,所以我们可以将其构造函数设置为私有,这样就防止用户滥用。
Runtime也是一个工具类,所以构造函数有私有的必要
那我们应该怎么构造呢?原本弹计算器应该是这样的:
Runtime.getRuntime().exec("calc");
可以看到是通过getRuntime()方法获得的实例化对象
那么我们可以先使用反射调用静态方法获得对象后再执行exec()
|
|
此例便可以弹出计算机了
如果将这些代码简化一下,就可以得到
|
|
常见的反射payload
如果就想使用newInstance()来获得构造呢,在之前获得对象中有提到
使用 Constructor 对象的 newInstance 方法获取反射类对象
所以可以先试试
|
|
但是依旧报错:

佬说需要通过setAccessible(true)来突破访问权限的检查
在一般情况下,我们使用反射机制不能对类的私有private字段进行操作,绕过私有权限的访问。但一些特殊场景存在例外的时候,比如我们进行序列化操作的时候,需要去访问这些受限的私有字段,这时我们可以通过调用AccessibleObject上的setAccessible()方法来允许访问。
Java.lang.reflect.AccessibleObject 类是Field,Method和Constructor类对象的基类,它提供了标记反射对象的能力,以抑制在使用时使用默认Java语言访问控制检查,从而能够任意调用被私有化保护的方法、域和构造函数,同时上述的反射类中的Field,Method和Constructor继承自AccessibleObject。所以我们在这些类方法基础上调用setAccessible()方法,既可对这些私有字段进行操作。
setAccessible()是AccessibleObject类的public函数,该类被Executable继承,之后Executable又被Constructor继承
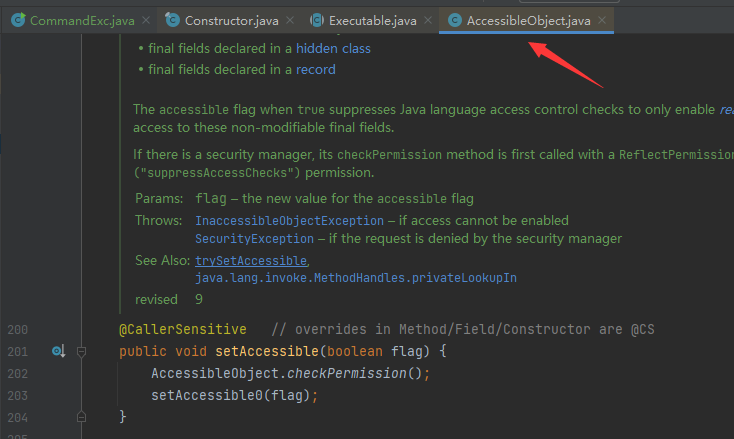


所以可以使用Field,Method和Constructor类的实例化对象去访问该函数,代码改进为:
|
|
还是报错,,,,
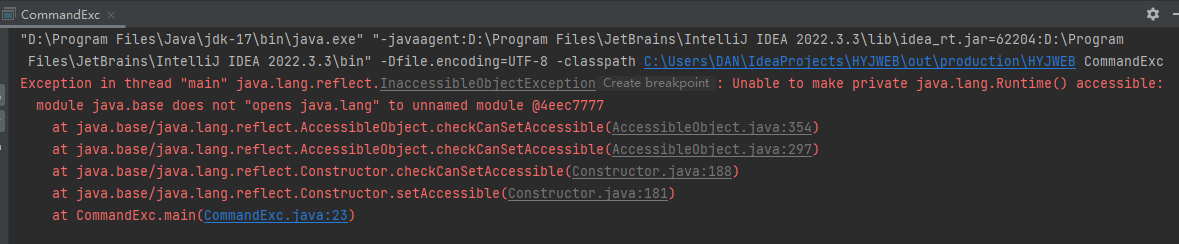
猜测是Java版本过新,解决办法:

如果没有类似我一样的方框的话,找到 Modify options ,去里面把
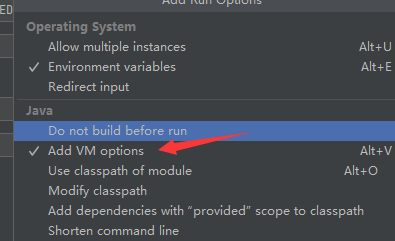
这个勾选上就有了,方框里填--add-opens java.base/java.lang=ALL-UNNAMED
最后运行,成功弹出计算器
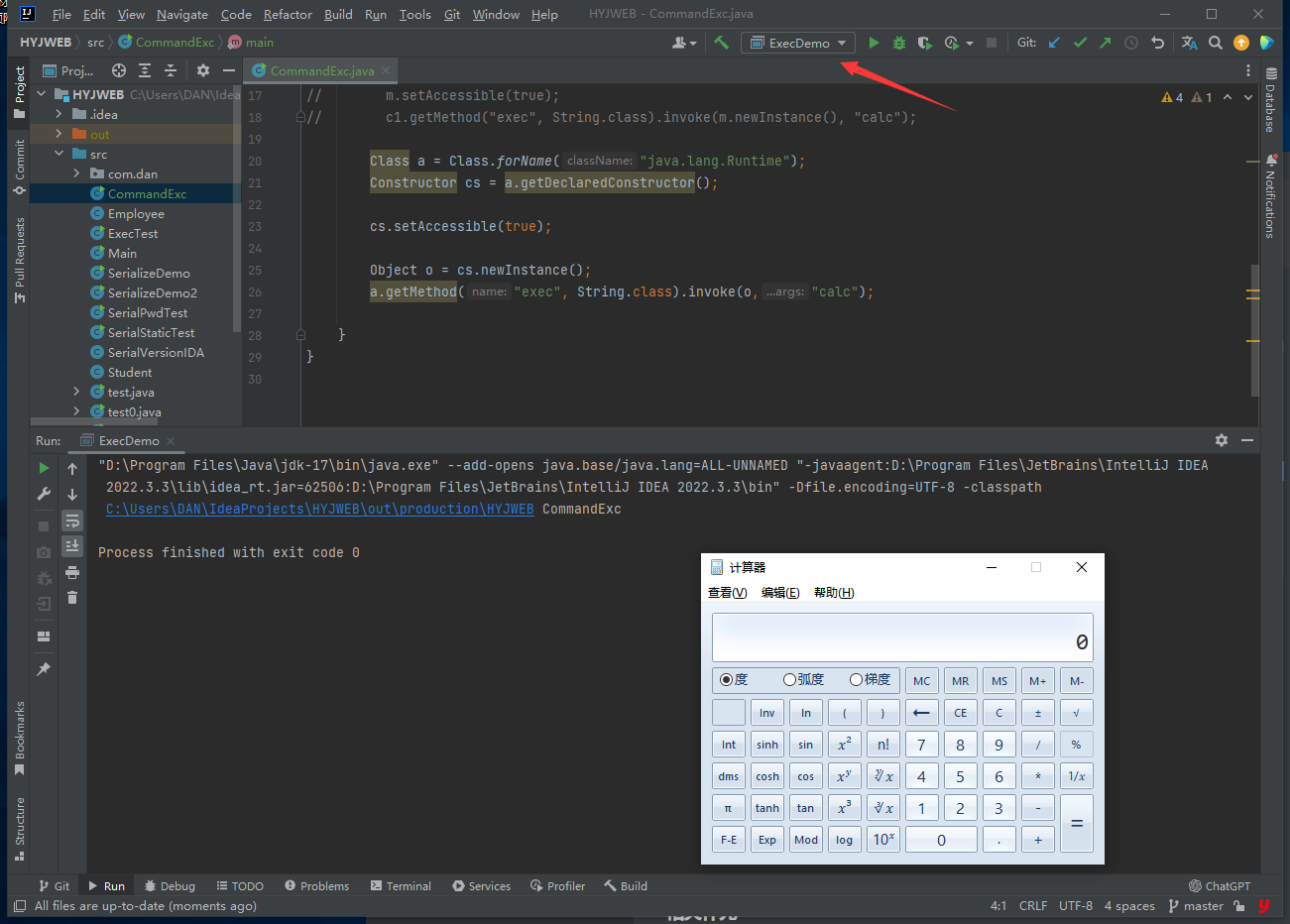
在实际利用场景当中,我们通常利用Java反射机制来绕过一些安全权限机制检查,如获取private权限的方法和属性。本质就是我们绕过访问安全检查。所以通过java反射机制的学习,能够为我们为我们后面的java漏洞分析调试,java漏洞poc测试和服务端模板引擎注入等有着十分重要的意义。
泛型
关于泛型的介绍可以参考链接(Java泛型详解,史上最全图文详解)
相关补充
Java中的Field类是反射机制的一部分,它的设计初衷是为了在运行时动态地获取和操作类的成员变量,包括私有变量。使用Field类可以获取类中的所有变量信息,包括变量名、类型、访问修饰符等,并可以通过它们进行读取、修改或设置新的值。 Field类的设计使得开发者可以在运行时获取和操作类的成员变量,这在某些情况下是非常有用的,例如:
- 当需要通过反射获取或设置某个类的私有变量时;
- 当需要动态地创建对象或者通过反射调用对象的方法时,需要访问对象中的成员变量;
- 当需要实现某些自定义的序列化或者反序列化机制时,需要获取或设置对象中的成员变量。
因此,Field类的设计初衷是为了提供一种方便的方式,使得开发者可以在运行时动态地获取和操作类的成员变量。
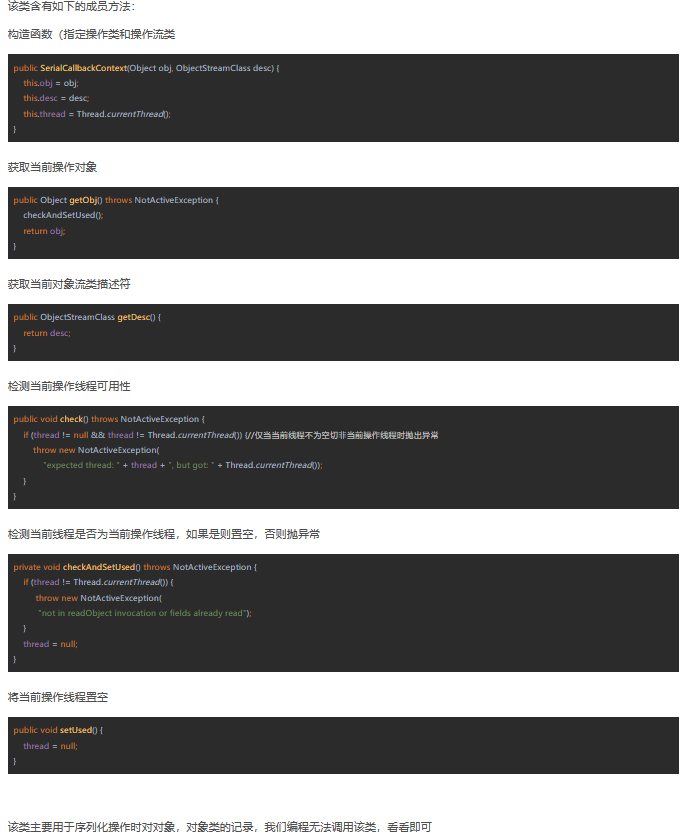
ctx 是一个 SerialCallbackContext 类对象, SerialCallbackContext类是内部类,无法在包(java.io)外引用,且该类为final,无法被继承,该类的描述:
大意就是
从对象流向上调用类定义的readObject/writeObject方法时的上下文。保存当前被反序列化的对象和当前类的描述符。这个上下文跟踪构造它的线程,并且只允许一个defaultReadObject, readFields, defaultWriteObject或writeFields的调用,这些必须在类的readObject/writeObject方法返回之前在同一个线程上调用。如果未设置为当前线程,getObj方法将抛出NotActiveException。
有如下成员变量:
被操作的Object,内含的对象流类,当前操作线程
|
|
参考链接
Java 日看一类(53)之IO包中的SerialCallbackContext类