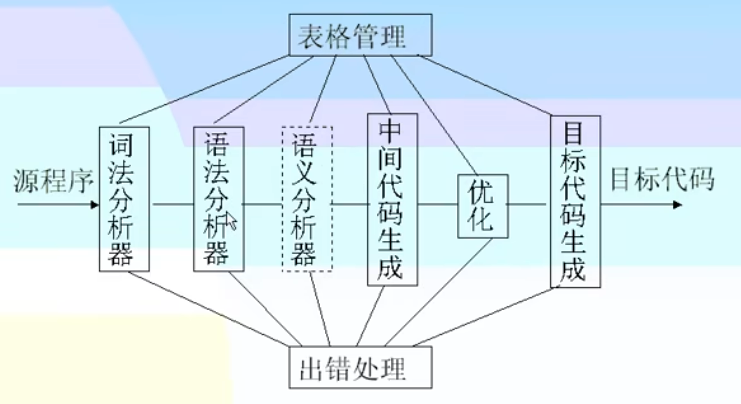
表格管理
-
作用:用来记录源程序的各种信息以及编译过程中的各种状况
-
与编译前三阶段有关的表格有:符号表、常数表、标号表、分程序入口表、中间代码表等
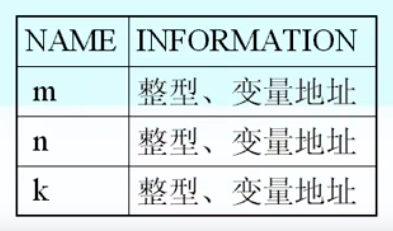
符号表
用来登记源程序中的常量名变量名、发数组名、过程名等,记录它们的性质、定义和引用情况
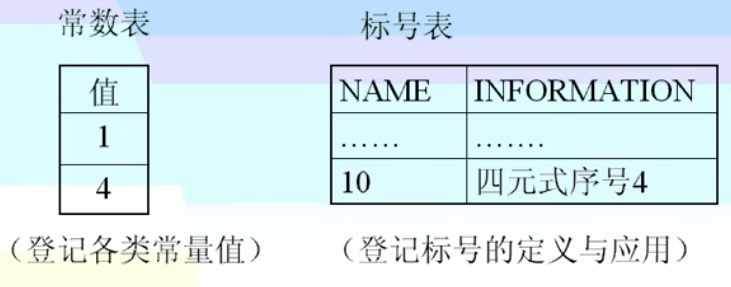
常数表与标号表
- 常数表:登记各类常量值
- 标号表:登记标号的定义与应用
例如 goto 代码后的标号,实际指向的是4元式的标号
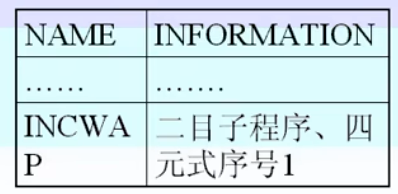
入口名表
- 登记过程的层号,分程序符号表入口等
中间代码表
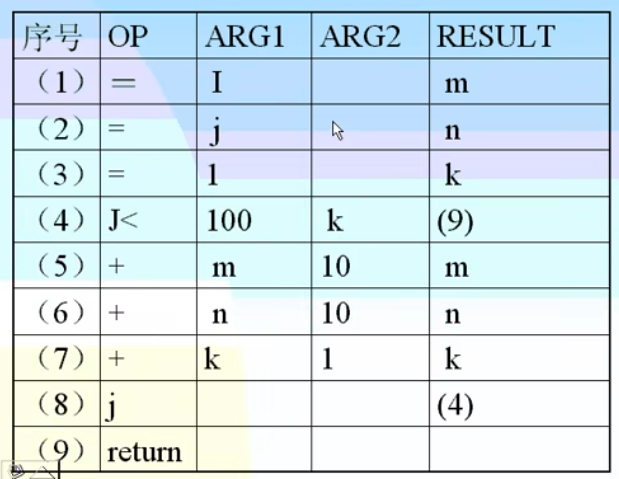
出错处理
- 如果源程序有错误,编译程序应当设法发现错误,并报告给用户
- 由专门的出错处理程序来完成
可以检查的错误类型有:
- 语法错误:在词法分析和语法分析阶段检测出来
- 语义错误:一般在语义分析阶段检测
遍
- 指对源程序或者源程序的中间结果从头到尾扫描一次,并做有关的加工处理,生成新的中间结果或者目标代码
- 与阶段的含义毫无关系
一遍扫描
以语法分析为中心
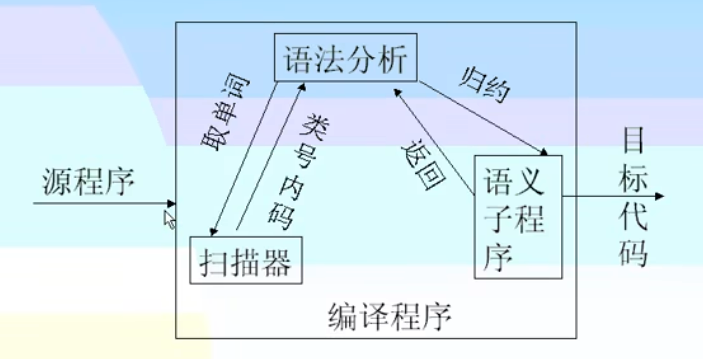
多遍扫描
- 优点:节省内存空间,提高目标代码质量,使得编译的逻辑结构清晰
- 缺点:编译时间较长
内存许可的情况下,遍数少一点
编译程序
- 直接用机器语言编写编译程序
- 用汇编编写编译程序,去适配某个语言
- 用高级语言编写编译程序(普遍使用)
自编译
例如Go语言的编译器是Go语言写的,这就叫做自编译
怎么做到的?语言开发的前期的编译器不是Go语言写的
- 优点:
- 缺点:
编译工具
-
LEX(词法分析)
-
YACC(用于自动产生LALR分析表)
基础知识
高级语言
程序语言是一个记号系统
- 语法
- 语义
语法

单词符号
- 语言中具有独立意义的最基本结构
- 单词符号一般包括:常数,标识符,基本字,算符,界限符等。
词法规则
语法规则
语法单位
- 语法单位一般包括:表达式,子句,语句,函数,过程,程序
语义
- 对于一个语言来说,不仅要给出它的词法、语法规则,而且要定义它的单词符号河语法单位的意义。
- 离开语义,语言只是一堆符号的集合。
- 各种语言中有形式上完全相同的语法单位,含义却不尽相同。
- 对某种语言,可以定义一个程序的意义的一组规则称为语义规则。
- 目前,大多数编译程序使用基于属性文法的语法制导翻译方法来分析语义。
文法
是描述语言的语法结构的形式规则
例子:Young men like pop music

非终结符
- 出现在规则的左部、用<>括起来、表示一定语法概念的词。

终结符
- 语言中不可再分割的字符串(包括单个字符组成的串)
终结符是组成句子的基本单位。

开始符号
- 表示所定义的语法范畴的非终结符
开始符号又称为识别符号
产生式
- 是用来定义符号串之间关系的一组(语法)规则
A -> a表示A产生a
推导
- 推导是从开始符号开始,通过使用产生式的右部取代左部,最终能产生语言的一个句子的过程。
- 最左(右)推导:每次使用一个规则,以其右部取代符号串最左(右)非终结符。
最左(右)推导被称为规范推导
归约
-
归约是推导的逆过程,即,从给定的源语言的句子开始,通过规则的左部取代右部,最终达到开始符号的过程。
-
最左(右)归约是最右(左)推导的逆过程。
最左归约和最右归约称为规范归约
句型,句子和语言


句子符合语法规则,但是不一定具有含义,所以语言是句子的子集
文法规则的递归
- 非终结符的定义中包含了非终结符自身
- 使用文法的递归定义要谨慎

文法规则的扩充表示
-
扩充的BNF表示
- 提因子:U->ax|ay|az 写为 U->a(x|y|z)
- 重复次数的指定

- 任选符号

元语言符号
|表示或者,->表示可以转化,这两个属于元语言符号
语法树
定义:用来表示语言句子结构的树
使用语法树可以使语法分析过程直观、形象,易于判断文法二义性
子树
除叶子结点之外的任意结点连同它的所有子孙结点构成子树。
修剪子树
剪去子树树根的所有孩子
句型
在一棵语法树生长过程中的任何时刻,所有那些叶子结点排列起来就是一个句型
短语
子树的末端符号自左到右述成串,相对于子树树根而言称为短语。
简单短语
也叫:直接短语。若短语事某子树根经过1步推导得到的,则称之为该子树根的简单短语。
句型的短语
该句型中哪些符号串可构成某子树根的短语。
句柄
句型中的最左简单短语,句柄是最左归约时要寻找的简单短语
文法与语言的关系
文法与语言的形式定义
Chomsky对文法的定义
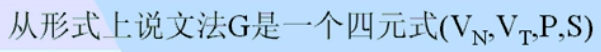
Chomsky对文法的分类

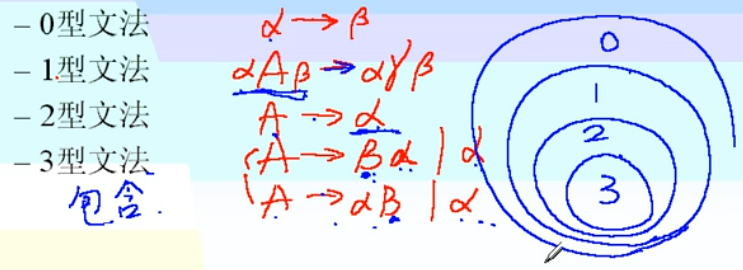
0型文法
短语文法,无限制文法
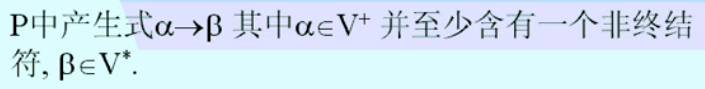
- 识别0型语言的自动机称为图灵机(TM)
- 0型文法是对产生式限制最少的文法
- 任何0型语言都是递归可枚举的
- 对0型文法产生式的形式作某些限制,可以得到其他类型文法的定义
1型文法
长度增加文法,上下文有关文法

或者也可以定义为:

- 识别1型语言的自动机称为线性界限自动机(LBA)
- 1型文法意味着,对非终结符进行替换时务必考虑上下文,并且,一般不允许替换成s,除非是开始符号产生ε
2型文法
上下文无关文法

-
2型文法对产生式的要求是:产生式左部一定是非终结符,产生式右部可以是VN、VT或ε;非终结符的替换不必考虑上下文
-
识别2型语言的自动机称为下推自动机(PDA)
3型文法
正规文法RG、左/右线性文法
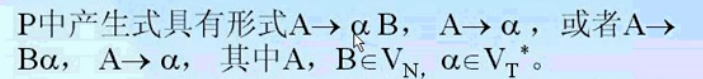
- 3型文法中的产生式要么均是右线性产生式,要么是左线性产生式,不能既有左线性产生式,又有右线性产生式。若所有产生式均是左线性,则称为左线性文法;若所有产生式均是右线性,则称为右线性文法
- 识别3型语言的自动机称为有限状态自动机。
总结
i型语
- 由i型文法生成的语言成为i型语言。
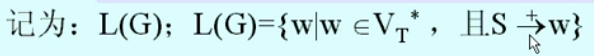
注意
在词法分析和语法分析中对产生式有限制
- 不存在P→P产生式
- 产生式中出现的任何非终结符P必须有用

文法的简化
- 同一语言可以用不同文法来描述,显然应当选择产生式的个数最少,最符合语言特征的来描述
- 在文法中,有些产生式对推导不起作用,要删除掉
- 如某个产生式在推导过程中永远不会被用到,即由开始符号推导,永远推不到的左部的非终结符。
- 再如永远导不出终结符串的产生式。
- 形如P→>P的产生式。
-
简化步骤:
- 查找有无形如P->P的产生式,若有则删除;
- 若某个产生式在推导过程中永远不会被用到,删除它;
- 若某个产生式在推导过程中不能从中导出终结符,删除它。
最后,整理所有剩余产生式,就得到简化的文法。
文法的二义性
句子二义性
如果文法的一个句子存在对应的两棵或两棵以上的语法树,则该句子是二义的
文法二义性
包含二义性句子的文法是二义文法
二义性会给语法分析带来不确定性
不存在一个算法能够在有限的步数内确定判断一个文法是否为二义文法,即文法的二义性是不可判定的
证明是二义性,只需要举例一个
若能控制文法的二义性,即加入人为的附加条件(确定优先级),则二义文法的存在并非坏事
笔者记
归约是更加符合编译程序逻辑的过程